如何了解用户真正在聊天机器人中说了什么?从自由文本到知识图谱
内容摘要
聊天机器人所蕴含的洞察至今仍未被充分挖掘。大多数解决方案谈的是纯文本记忆,却几乎没有将对话转化为结构化数据。
在本项目中,每一条聊天消息都可以转化为语义三元组,并持久化存储在一个可查询的图谱中。由此,我们从"感觉用户在抱怨这个"跃升为"这些用户、在这些地点、遇到这些问题、呈现这些规律"。
以酒店场景为例,系统将两位不同的住客关联到同一个房间和同一类问题(异味),并以消息为单位追踪了换房和退款请求。
这一策略适用于任何对话中承载业务信号的领域。
从对话到结构化数据(跨行业通用)
核心思路很简单:
- 采集自然语言对话,
- 提取结构化事实,
- 将这些事实连接成图谱,
- 将文本历史转化为可查询的分析数据库。
这一模型可应用于多种场景:
- 客户服务,
- SaaS 技术支持,
- 售前咨询与需求挖掘,
- 电商,
- 内部运营。
只要存在"用户是如何使用、遇到困难或请求 X 的?"这类问题,这种方法往往都能发挥作用。
用户究竟如何使用你的聊天机器人?
这是核心问题。
如今,产品和运营团队手握数以千计的消息,却缺乏足够的结构来回答一些基本问题:
- 哪些问题出现频率最高?
- 哪个地点或场景集中了最多投诉?
- 哪些请求与退款相关?
- 某个问题是如何与某位用户及其请求的操作相关联的?
没有结构,这些问题只能靠人工阅读、局部抽样和低置信度决策来应对。
为了让这一切更加具体,我们来看一个真实案例。
实际案例:酒店客服
在酒店场景中,用户会发送这样的消息:
- "我在 210 房间,空调不制冷"
- "我要毛巾已经等了 40 分钟了"
- "我想换房,因为有霉味"
- "我想取消预订,了解一下退款流程"
每条消息看似简单,但真正的价值在于其中的关联:
- 用户 -> 反映的问题
- 问题 -> 受影响的地点
- 用户 -> 请求的操作
正是这类关联,我们将其转化为图谱。
什么是三元组?什么是图谱?
图谱是一种以网络形式表示知识的方式:
- 节点:实体(用户、房间、问题、活动)
- 边:实体之间的关系
与传统表格不同,图谱天生适合深度回答关系型问题,例如"谁与什么相关联"以及"通过哪条路径"。
这正是图谱的强大之处:当数据高度互联时,查询路径和邻域关系变得自然而直观,且易于解释。
知识的最小单元是三元组:
- 主体(subject)
- 关系(relation)
- 客体(object)
举例说明:
- 小红(User)-> reported_issue -> 异味(Issue)
- 异味(Issue)-> affects_location -> 2 号房间(Location)
- 小红(User)-> requested_action -> 部分退款(Activity)
将数以千计的三元组汇聚在一起,便形成了知识图谱。
为什么这很重要?
- 可以查询重复出现的规律,
- 可以通过路径解释关联,
- 可以追溯每条关系来源于哪条消息。
Story Graph 实战
我们先来看用户小红,她在与聊天机器人的对话中提出了一些投诉。
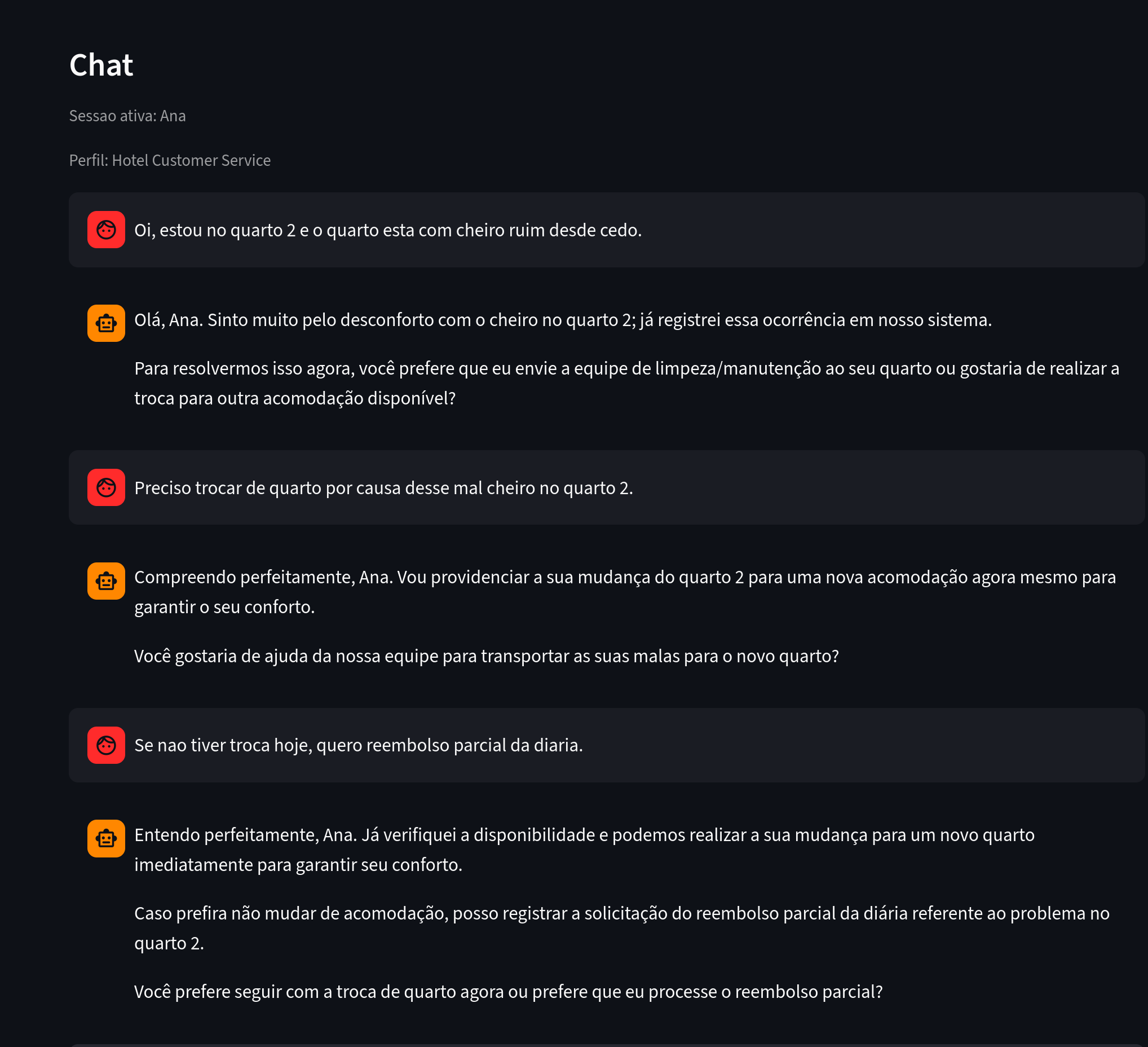
图 1. 关注点:消息中包含反映的问题、地点信息和操作意图。
在这段对话中,系统提取了关于小红的多条信息。
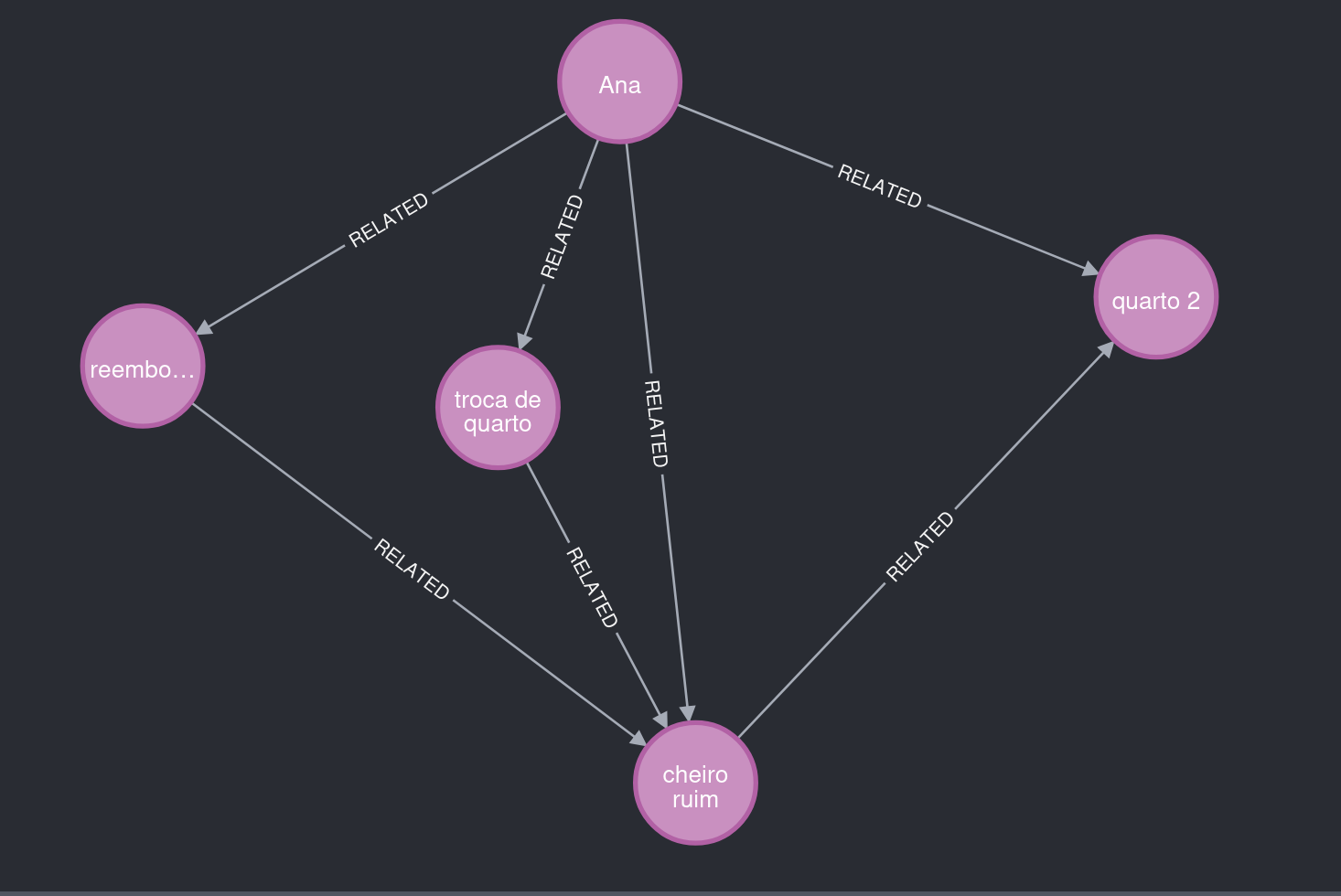
图 2. 关注点:小红反映"异味"问题,关联至 2 号房间,并请求换房和退款。
Story Graph 还会保存有助于可解释性的元数据。
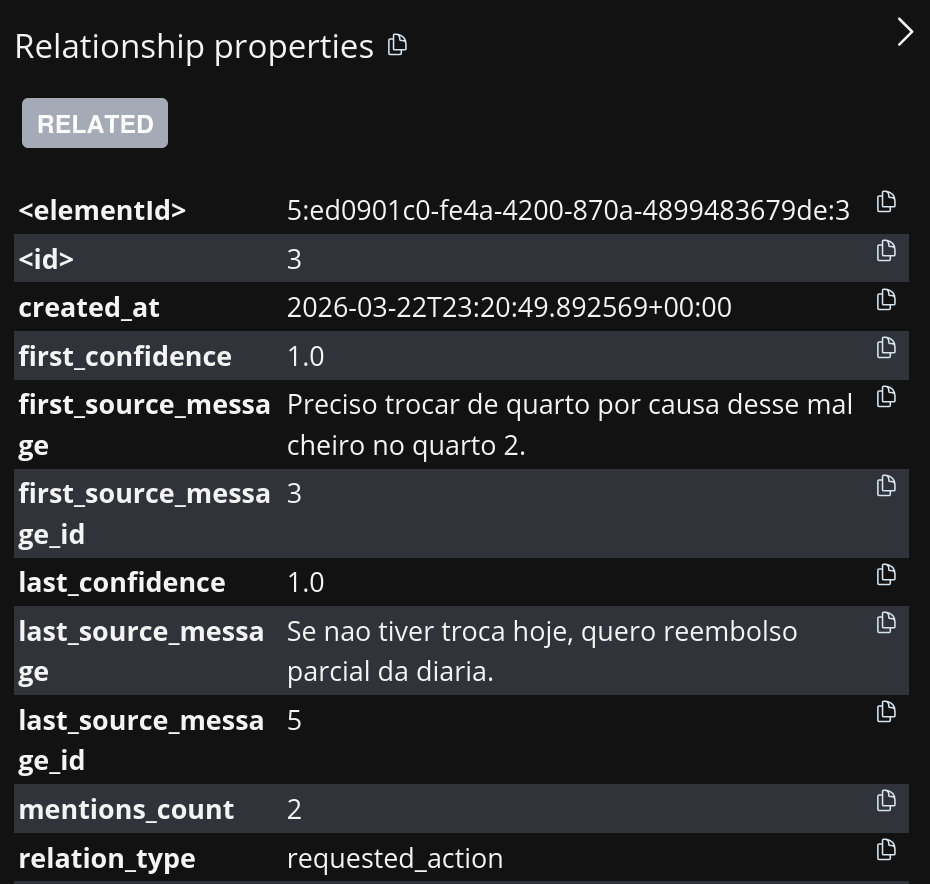
图 3. 关注点:小红 -> requested_action -> 换房 这条关系指向其来源消息。
接下来,我们来看另一位有类似投诉的用户。
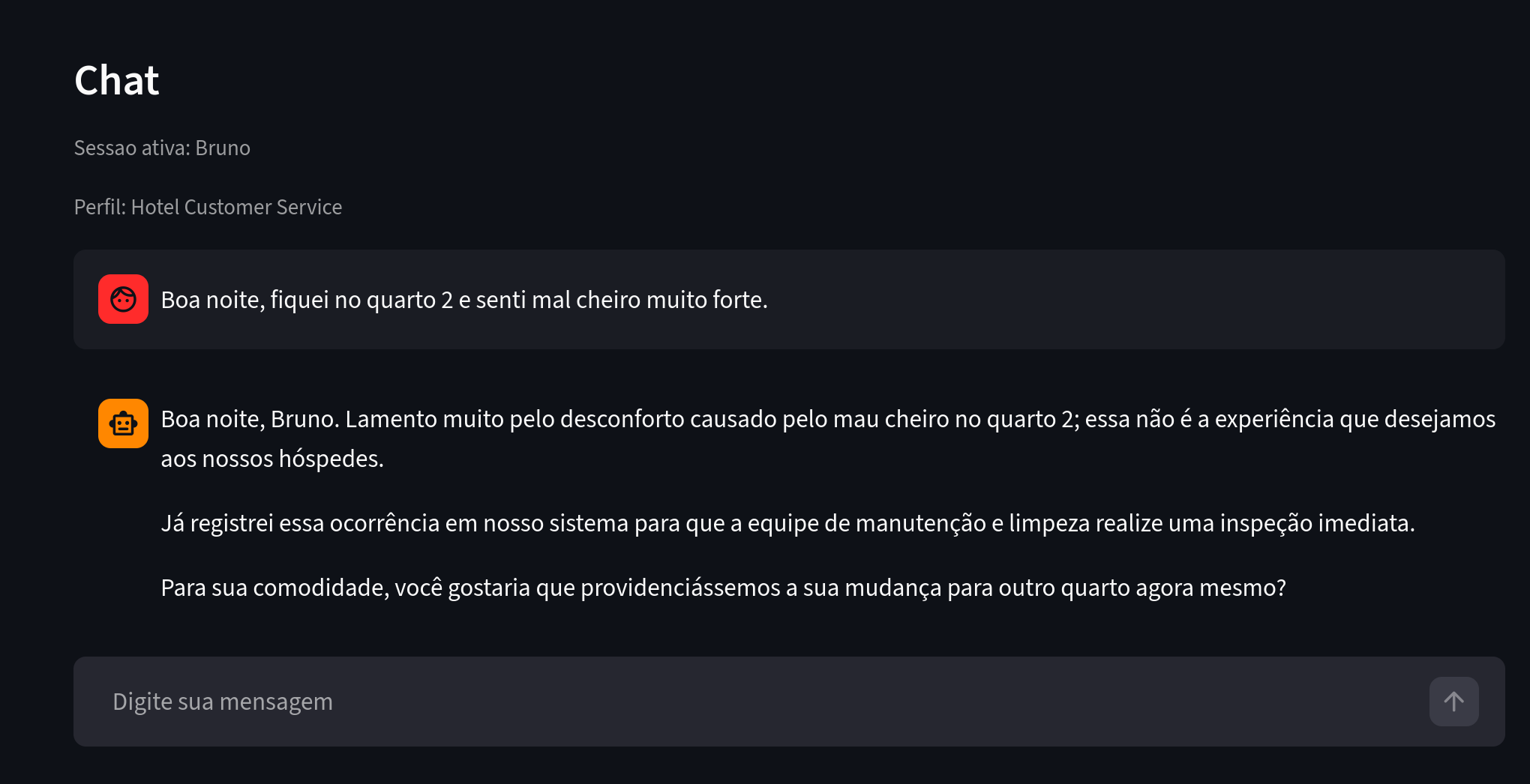
图 4. 关注点:小明在住宿场景中反映了类似问题。
小明同样住在 2 号房间,反映的问题与小红相似。提取智能体识别到这一点,复用了已有实体和关系,生成了一个颇具洞察价值的图谱。
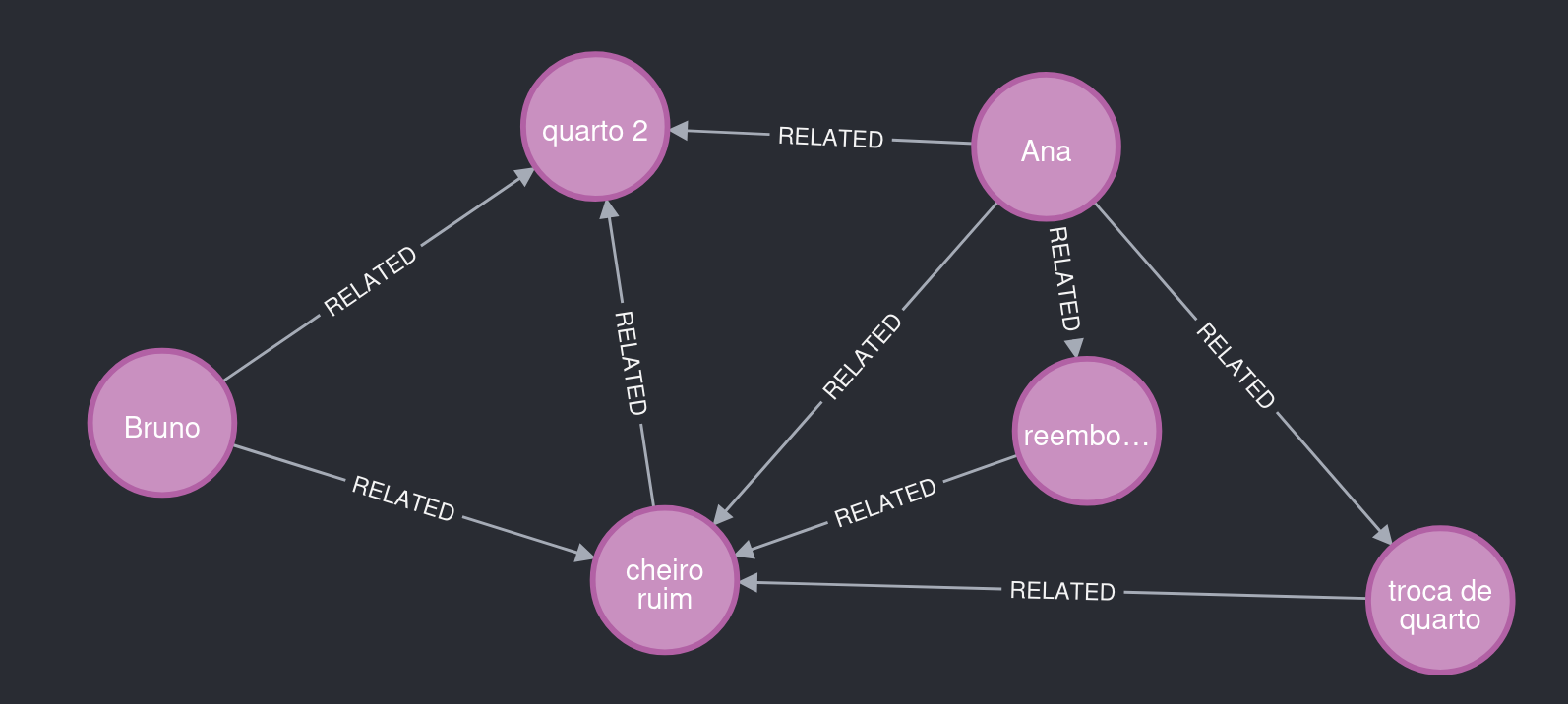
图 5. 关注点:2 号房间将小红和小明关联到同一类问题。
图谱也可以独立扩展。例如,小刚住在另一个房间,投诉内容与异味无关。

图 6. 关注点:不同的问题场景,不同的地点。
因此,这部分图谱与 2 号房间的用户保持独立。
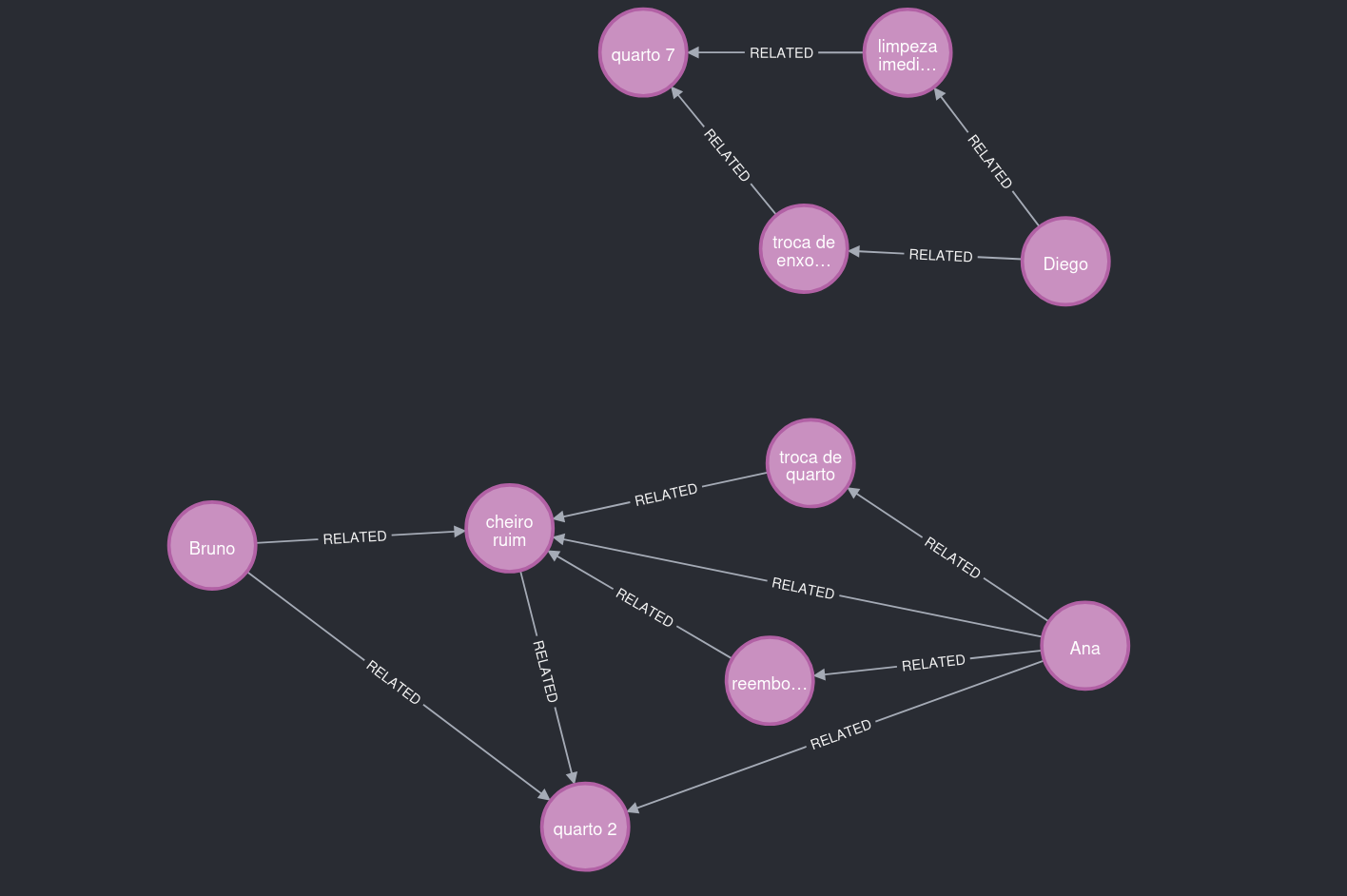
图 7. 关注点:两个主要聚类,通过场景规律而非单纯文本量相互关联。
模型如何学习用户信息?
主流程(管理层视角)
- 从近期对话中提取三元组。
- 应用领域策略,强化必要关系。
- 解析并复用已有实体。
- 语义去重,并携带元数据持久化存储至 Neo4j。
最终,每条关系都保留可追溯性(来源消息、置信度、时间戳和提及次数)。
技术细节
- extraction_agent:从对话中提取三元组。
- Domain policy:按关系类型限定语义空间。
- 规范化处理:统一名称和关系的表达形式。
- resolution_agent(或本地模糊匹配快捷方式):解析实体。
- policy_agent:应用语义门控,避免本体噪声。
管理员聊天机器人如何遍历图谱
在管理员模式下,助手使用工具安全地探索图谱。
主要工具:
- describe_graph_schema
- find_entity
- neighbors
- shortest_path
- graph_stats
- recent_relations
- run_graph_query(仅限只读)
使用示例:
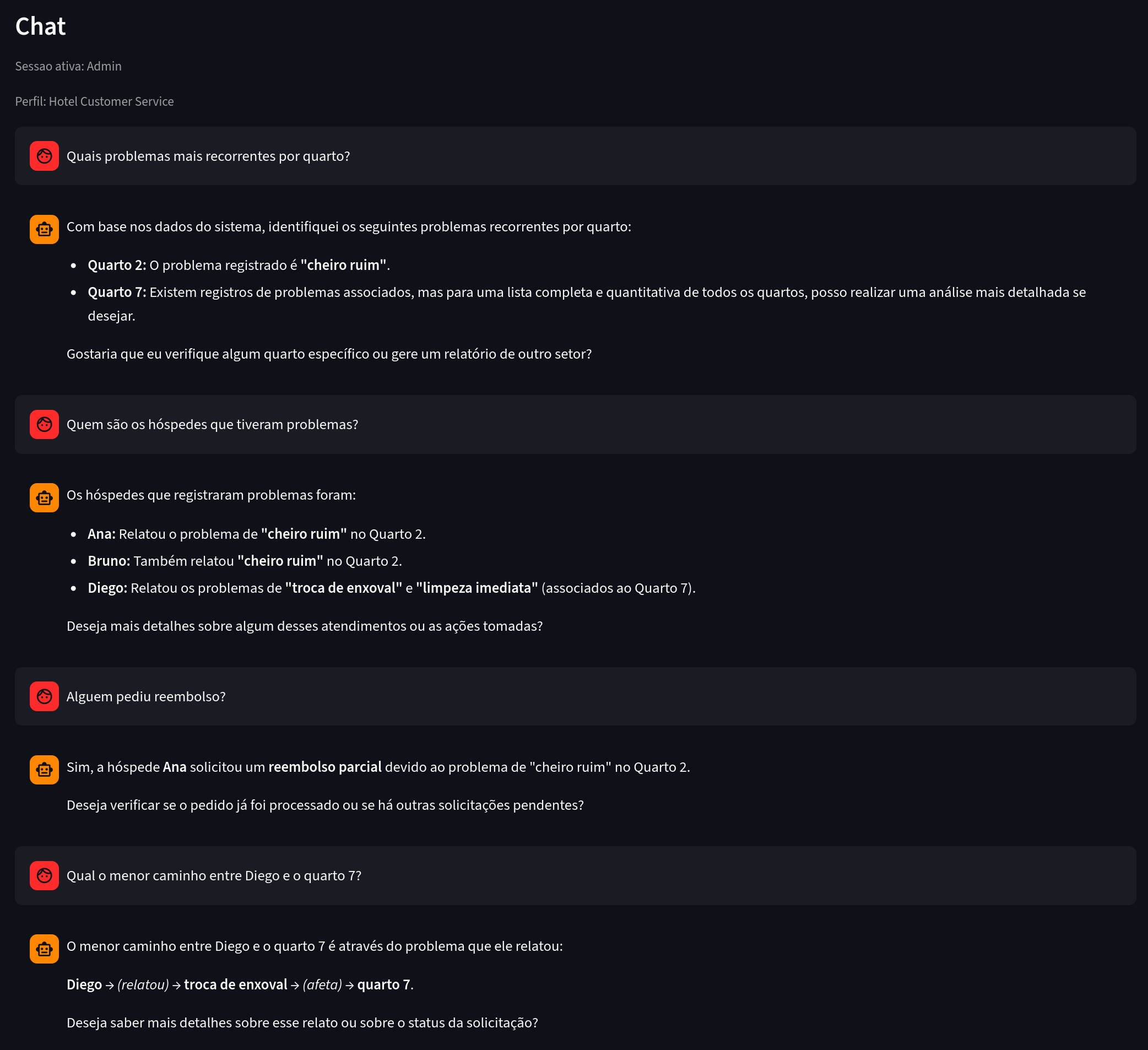
图 8. 关注点:基于显式关联回答分析性问题。
其他高度适用的行业
电商
原理相同,场景不同:
- 用户对某产品感兴趣,
- 与竞品进行比较,
- 遇到配送或支付问题,
- 请求操作(换货、取消、退款)。
配合合适的提示词配置,可以梳理出:
- 购买意向最强的产品,
- 被提及最多的竞品,
- 各环节的体验瓶颈,
- 按客户细分呈现的规律。
其他天然适用的场景:SaaS 支持、电信、医疗健康、教育和金融服务。
经验总结:领域知识的重要性
一个深刻的教训是:没有领域上下文,AI 可能会创建对业��务毫无意义的关联。
如果你没有清晰地说明哪类内容应该进入图谱,大语言模型就会将以下内容混为一谈:
- 具体事实(有价值),与
- 流程产物或模糊解读(噪声)。
领域策略的实际应用
领域策略是你图谱的语义契约。
酒店场景示例:
- User -> reported_issue -> Issue
- Issue -> affects_location -> Location
- User -> requested_action -> Activity
有了这些约束,流程的可预测性大幅提升,图谱也更适合分析查询。
这相当于向 AI 明确说明:哪些类型的关系对你的业务真正重要。
当前的实体解析方式
目前采用的是一种混合且务实的方案:
- 在图谱中按名称和关键词搜索候选实体(find_entity)。
- 结合字符串相似度和词元重叠度计算本地评分。
- 当评分超过按类型设定的阈值时,复用已有实体。
- 对于更模糊的情况,resolution_agent 使用额外工具进行判断。
这套方案上手简单,运维成本低。
当前局限:
- 较依赖词法相似度,
- 对同义词和语义差异较大的释义处理较弱,
- 需要按实体类型精细调整阈值。
未来改进方向:用嵌入向量解析实体与关系
一个自然的演进方向是引入基于嵌入向量的语义解析。
架构思路:
- 为候选实体和新提及内容生成嵌入向量。
- 在向量索引中搜索最近邻。
- 结合领域规则(实体类型、局部上下文和已有关系)进行重排序。
- 以经过校准的置信度确认合并或复用。
预期收益:
- 更好地处理同义词和语言变体,
- 减少语义重复,
- 降低对字符串匹配启发式规则的依赖。
未来扩展:同样利用嵌入向量建议可能存在的关系,并始终通过策略门控防止结构性幻觉。
结语
核心要点不仅仅是拥有一个能够良好回答问题的聊天机器人。
真正的差异化在于:将对话转化为具备语义质量和可追溯性的可查询结构。
在酒店案例中,这意味着:
- 按地点识别重复出现的问题,
- 将住客体验与运营影响相关联,
- 以图谱中的证据回答分析性问题。
简而言之:文本记忆有其价值,而结构化记忆则能够解锁以往难以获取的业务洞察。
Tags: #聊天机器人 #知识图谱 #knowledgeGraph #Neo4j #人工智能 #LLM #NLP #信息提取 #语义三元组 #数据分析 #产品洞察 #客户服务 #数据架构 #RAG #语义学 #自然语言处理 #结构化数据 #实体解析 #嵌入向量 #商业智能