आपके उपयोगकर्ता आपके चैटबॉट का उपयोग कैसे करते हैं? मुक्त पाठ से ज्ञान ग्राफ तक
संक्षेप में (TL;DR)
चैटबॉट से मिलने वाली अंतर्दृष्टि अभी भी काफी हद तक अनछुई है। अधिकांश समाधान केवल सादे पाठ में स्मृति की बात करते हैं, लेकिन बातचीत को संरचित डेटा में बदलने पर लगभग कोई ध्यान नहीं देते।
इस परियोजना में, चैट का प्रत्येक संदेश सिमेंटिक ट्रिपल्स में बदल सकता है, जो एक क्वेरी योग्य ग्राफ में संग्रहीत होते हैं। इससे हम "लगता है उपयोगकर्ता इसकी शिकायत करते हैं" से निकलकर "ये उपयोगकर्ता, इन स्थानों पर, इन समस्याओं के साथ, इन पैटर्न में" तक पहुँचते हैं।
होटल के उदाहरण में, सिस्टम ने दो अलग-अलग मेहमानों को एक ही कमरे और एक ही प्रकार की समस्या (बुरी गंध) से जोड़ा, और संदेश-स्तर की ट्रेसेबिलिटी के साथ कमरा बदलने और धनवापसी के अनुरोधों की पहचान की।
और यह रणनीति किसी भी ऐसे क्षेत्र में काम करती है जहाँ बातचीत में व्यावसायिक सं��केत होते हैं।
बातचीत से संरचित डेटा तक (क्षेत्र से परे)
मूल विचार सरल है:
- आप प्राकृतिक भाषा में बातचीत एकत्र करते हैं,
- संरचित तथ्य निकालते हैं,
- उन तथ्यों को एक ग्राफ में जोड़ते हैं,
- और पाठ्य इतिहास को एक क्वेरी योग्य विश्लेषणात्मक आधार में बदलते हैं।
इस मॉडल का उपयोग कई परिदृश्यों में किया जा सकता है:
- ग्राहक सेवा,
- SaaS तकनीकी सहायता,
- प्री-सेल्स और डिस्कवरी,
- ई-कॉमर्स,
- आंतरिक संचालन।
जब भी "उपयोगकर्ता X का उपयोग, अनुभव या अनुरोध कैसे कर रहे हैं?" जैसा प्रश्न हो, यह दृष्टिकोण अच्छा काम करता है।
आपके उपयोगकर्ता आपके चैटबॉट का उपयोग कैसे करते हैं?
यही केंद्रीय प्रश्न है।
आज, उत्पाद और संचालन टीमों के पास हजारों संदेश हैं, लेकिन सरल प्रश्नों का उत्तर देने के लिए बहुत कम संरचना है:
- कौन सी समस्याएँ सबसे अधिक सामने आती हैं?
- कौन सा स्थान या संदर्भ सबसे अधिक शिकायतें केंद्रित करता है?
- कौन से अनुरोध धनवापसी से जुड़े हैं?
- कोई समस्या किसी उपयोगकर्ता और किसी अनुरोधित कार्रवाई से कैसे जुड़ती है?
संरचना के बिना, यह सब मैन्युअल पठन, आंशिक नमूनाकरण और कम विश्वास के साथ निर्णय लेने में बदल जाता है।
इसे ठोस बनाने के लिए, चलिए एक वास्तविक उदाहरण देखते हैं।
व्यावहारिक उदाहरण: होटल सेवा
होटल परिदृश्य में, उपयोगकर्ता इस तरह की बातें लिखता है:
- "मैं कमरा 210 में हूँ और एसी ठंडा नहीं कर रहा"
- "मैंने 40 मिनट पहले तौलिया माँगा था"
- "फफूंद की गंध के कारण मैं कमरा बदलना चाहता हूँ"
- "मैं रद्द करना चाहता हूँ और धनवापसी के बारे में जानना चाहता हूँ"
हर संदेश सरल लगता है, लेकिन असली मूल्य कनेक्शन में है:
- उपयोगकर्ता -> रिपोर्ट की गई समस्या
- समस्या -> प्रभावित स्थान
- उपयो��गकर्ता -> अनुरोधित कार्रवाई
और यही कनेक्शन हम ग्राफ में बदलते हैं।
ट्रिपल क्या है? और ग्राफ क्या है?
ग्राफ ज्ञान को एक नेटवर्क के रूप में दर्शाने का एक तरीका है:
- नोड्स: इकाइयाँ (उपयोगकर्ता, कमरा, समस्या, गतिविधि)
- किनारे: इन इकाइयों के बीच संबंध
पारंपरिक तालिका के विपरीत, ग्राफ को गहराई के साथ संबंधात्मक प्रश्नों का उत्तर देने के लिए बनाया गया है, जैसे "कौन किससे जुड़ा है" और "किस रास्ते से"।
इसीलिए यह इतना शक्तिशाली है: जब डेटा अत्यधिक जुड़ा हुआ होता है, तो पथों और पड़ोसियों की क्वेरी करना स्वाभाविक और स्पष्ट हो जाता है।
यहाँ ज्ञान की सबसे छोटी इकाई ट्रिपल है:
- subject (विषय)
- relation (संबंध)
- object (वस्तु)
प्रकारों के साथ उदाहरण:
- Ana (User) -> reported_issue -> बुरी गंध (Issue)
- बुरी गंध (Issue) -> affects_location -> कमरा 2 (Location)
- Ana (User) -> requested_action -> आंशिक धनवापसी (Activity)
जब हम हजारों ऐसे ट्रिपल्स को एक साथ जोड़ते हैं, तो एक ज्ञान ग्राफ बनता है।
यह क्यों मायने रखता है?
- पुनरावृत्ति की क्वेरी की जा सकती है,
- पथों के माध्यम से कनेक्शन समझाए जा सकते हैं,
- यह ट्रैक किया जा सकता है कि प्रत्येक संबंध किस संदेश से आया।
व्यवहार में Story Graph
चलिए उपयोगकर्ता Ana से शुरू करते हैं, जो चैटबॉट से बात करते हुए कुछ शिकायतें लाती है।
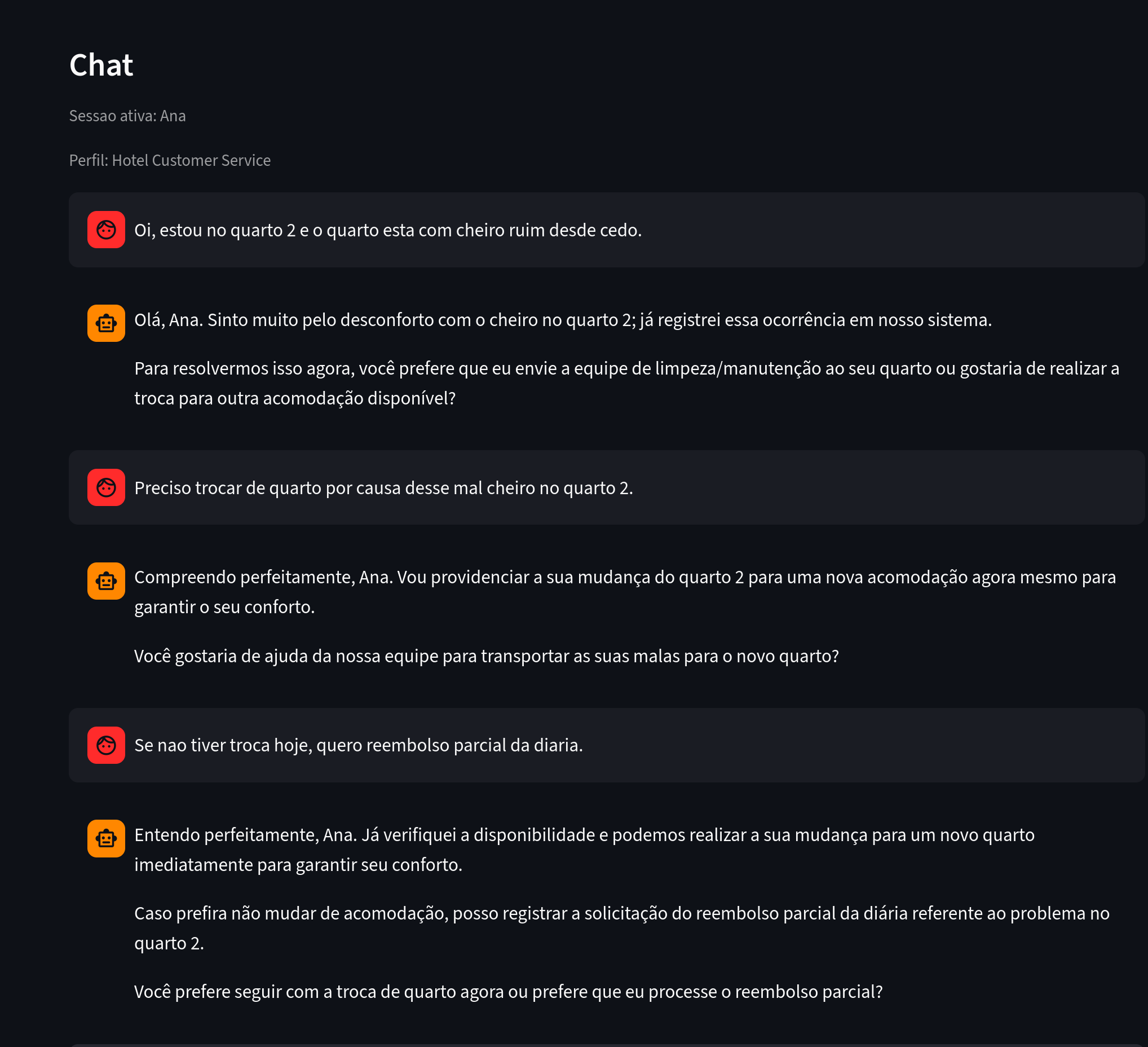
चित्र 1. ध्यान दें: रिपोर्ट की गई समस्या, स्थान और कार्रवाई के इरादे वाले संदेश।
इस चैट में Ana के बारे में कई जानकारियाँ निकाली गईं।
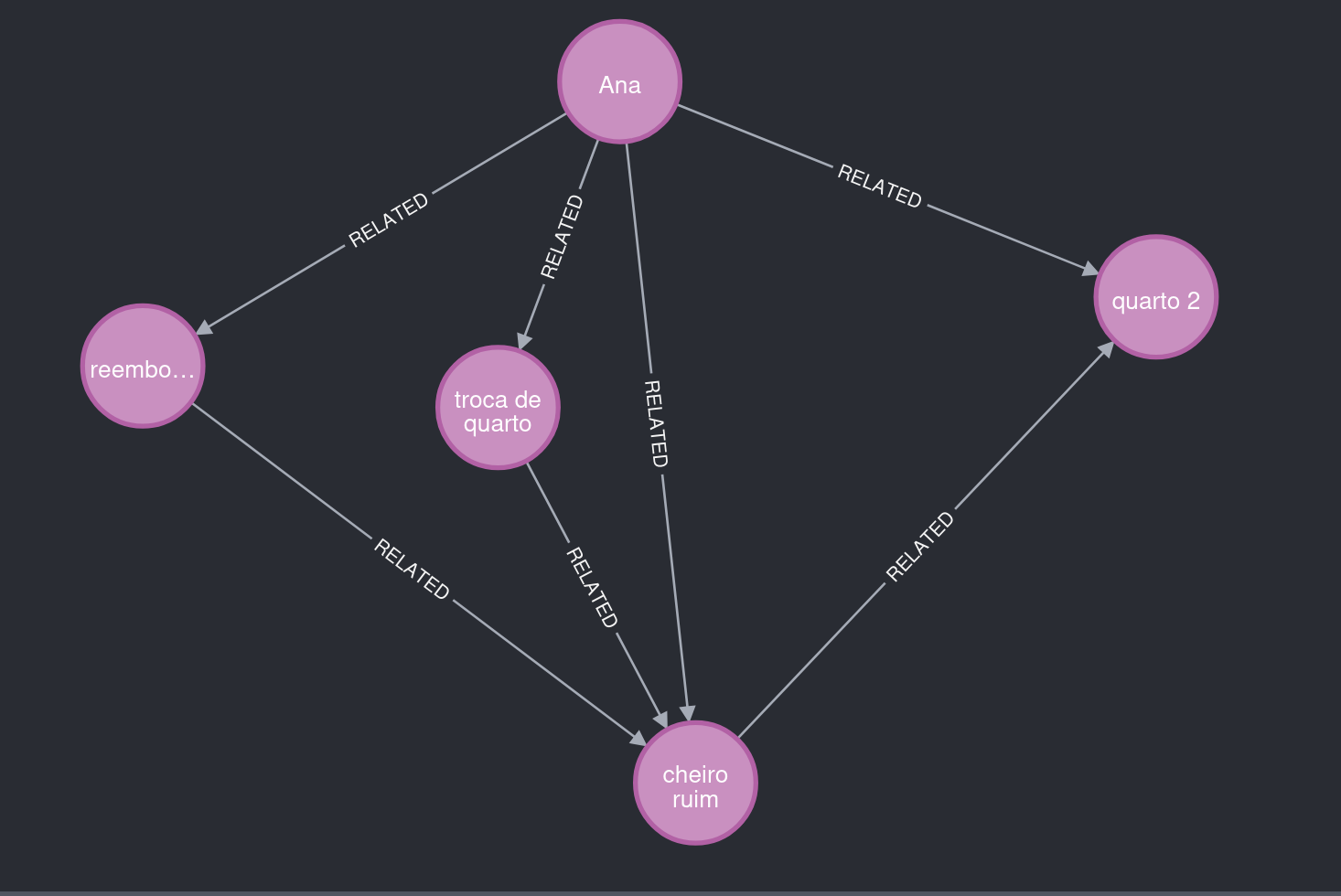
चित्र 2. ध्यान दें: Ana "बुरी गंध" रिपोर्ट करती है, जो कमरा 2 से जुड़ी है, और कमरा बदलने व धनवापसी का अनुरोध करती ह��ै।
Story Graph ऐसे मेटाडेटा भी सहेजता है जो स्पष्टता में मदद करते हैं।
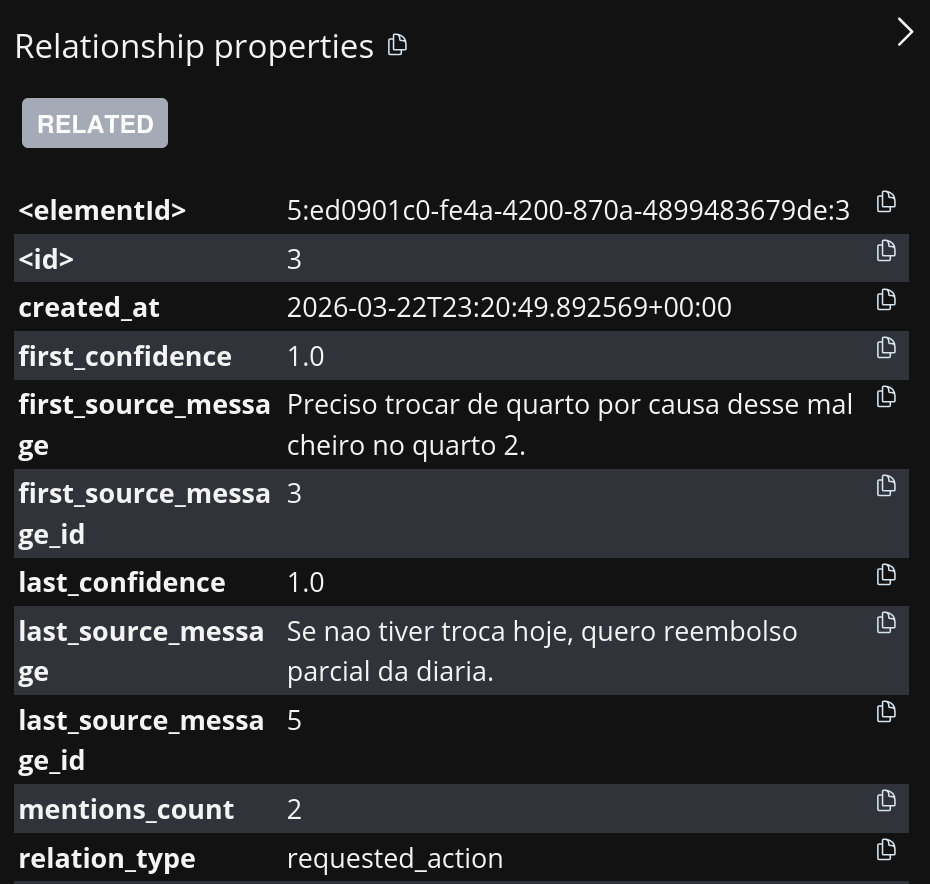
चित्र 3. ध्यान दें: Ana -> requested_action -> कमरा बदलना संबंध मूल संदेश की ओर इशारा करता है।
अब चलिए एक अन्य उपयोगकर्ता को देखते हैं जिसकी शिकायतें समान हैं।
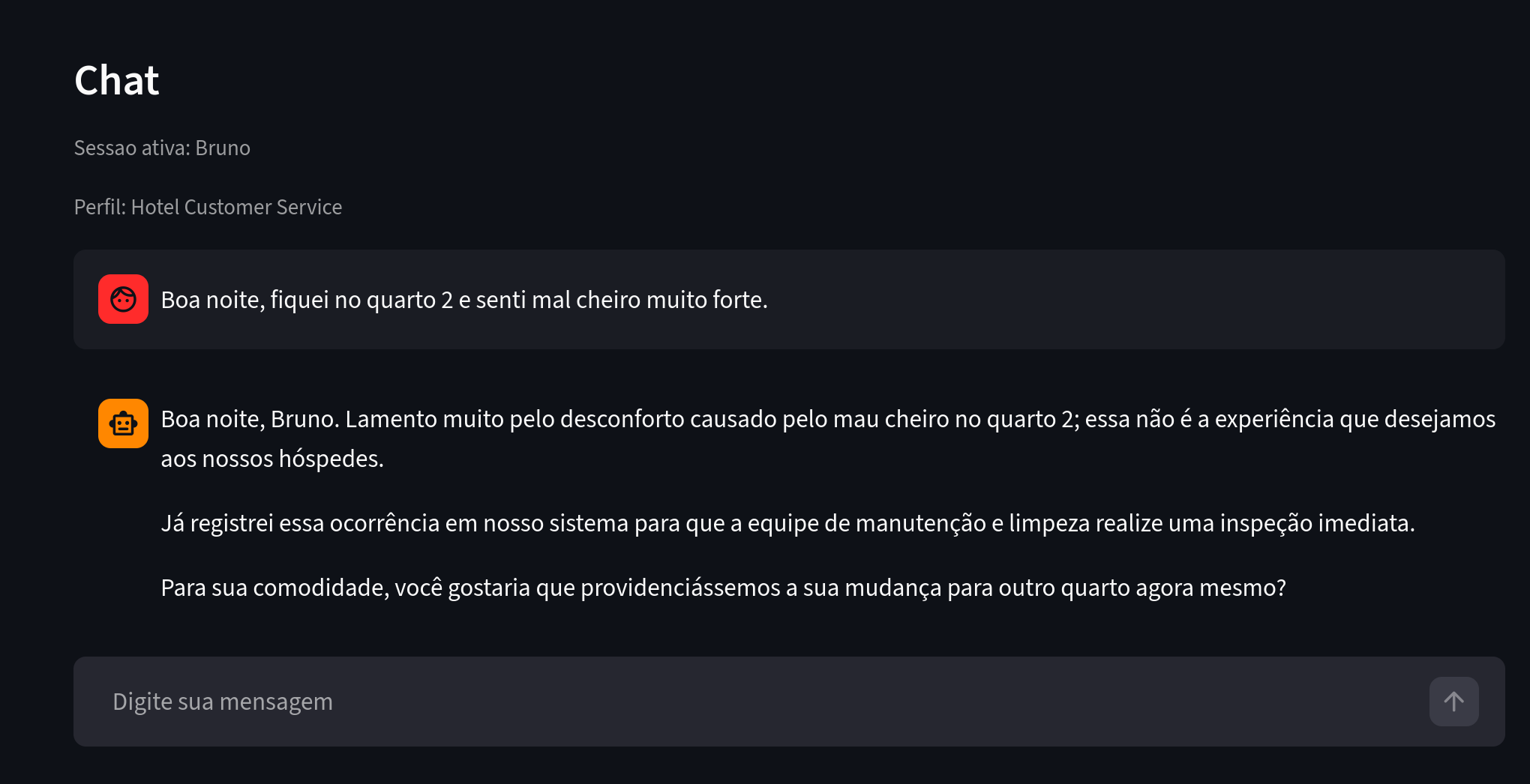
चित्र 4. ध्यान दें: Bruno होटल में रहने के संदर्भ में समान समस्या की रिपोर्ट करता है।
Bruno भी कमरा 2 में था और उसने Ana जैसी ही समस्या रिपोर्ट की। एक्सट्रैक्टर एजेंट ने इसे पहचाना और इकाइयों व संबंधों का पुनः उपयोग किया, जिससे रोचक अंतर्दृष्टि वाला ग्राफ बना।
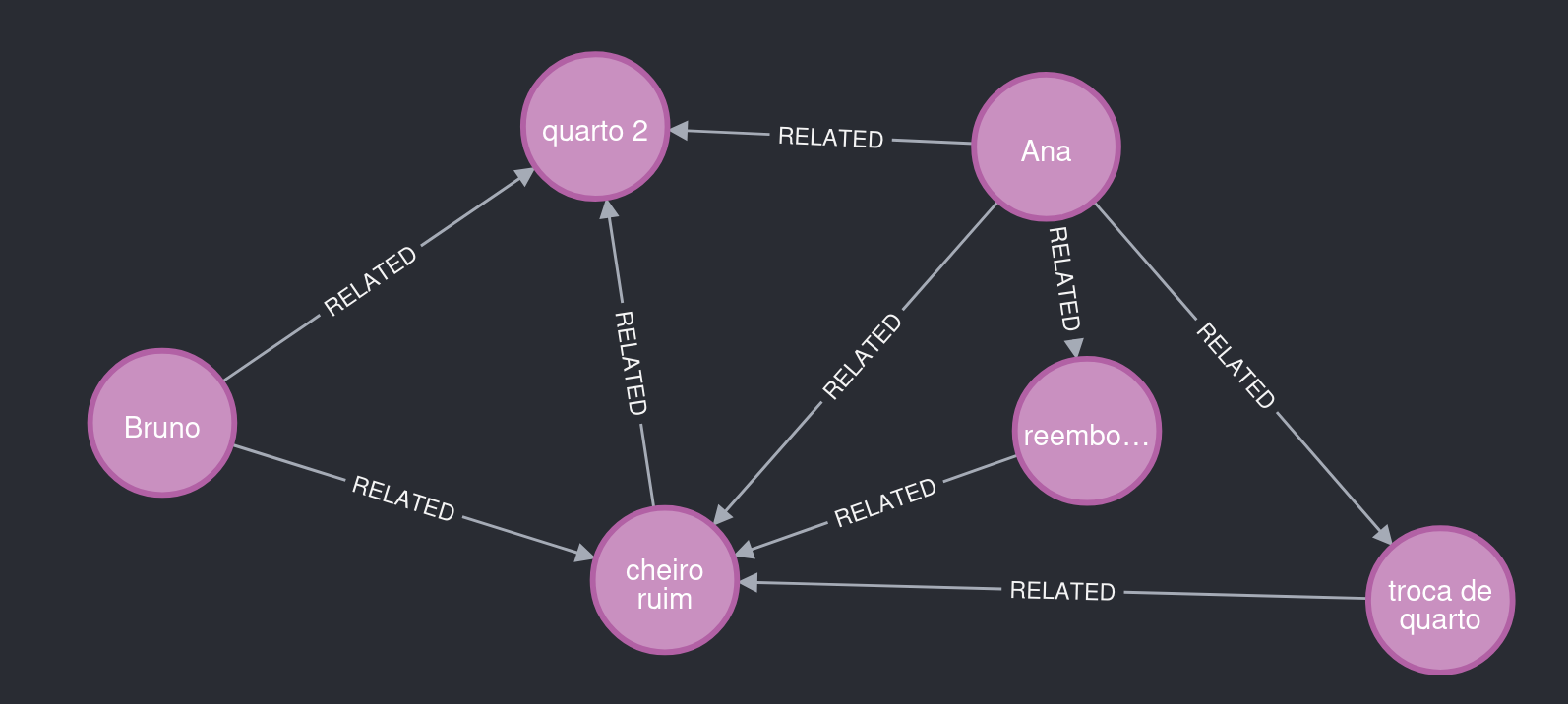
चित्र 5. ध्यान दें: कमरा 2 Ana और Bruno को एक ही प्रकार की समस्या से जोड़ता है।
ग्राफ अलग-अलग भी बढ़ सकता है। उदाहरण के लिए, Diego किसी अन्य कमरे में था और उसकी शिकायतें गंध से संबंधित नहीं थीं।

चित्र 6. ध्यान दें: एक अलग समस्या का संदर्भ और एक अलग स्थान।
इसीलिए ग्राफ का यह हिस्सा कमरा 2 के उपयोगकर्ताओं से अलग रहा।
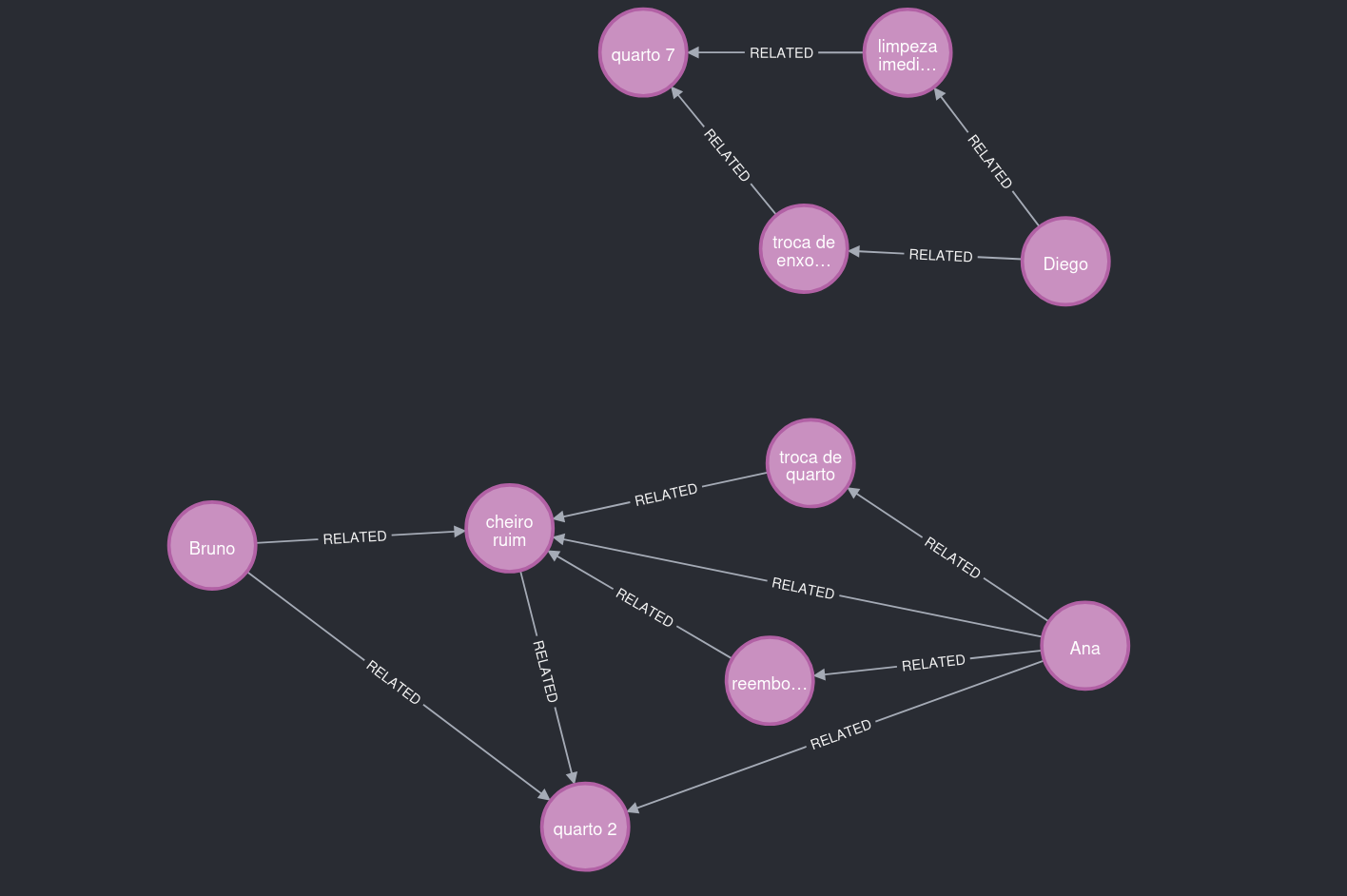
चित्र 7. ध्यान दें: दो मुख्य समूह, जो केवल पाठ की मात्रा से नहीं बल्कि संदर्भ के पैटर्न से जुड़े हैं।
मॉडल उपयोगकर्ताओं के बारे में कैसे सीखता है?
मुख्य पाइपलाइन (कार्यकारी दृष्टिकोण)
- हालिया बातचीत से ट्रिपल्स निकालना।
- अनिवार्य संबंधों को मजबूत करने के लिए डोमेन नीति लागू करना।
- मौजूदा इकाइयों का समाधान और पुनः उपयोग।
- सिमेंटिक डिडुप और Neo4j में मेटाडेटा के साथ संग्रहण।
अंत में, प्रत्येक सहेजे गए संबंध में ट्रेसेबिलिटी होती है (मूल संदेश, विश्वास स्तर, टाइमस्टैम्प और उल्लेख काउंटर)।
तकनीकी पर्दे के पीछे
- extraction_agent बातचीत से ट्रिपल्स निकालता है।
- Domain policy संबंध प्रकार के अनुसार सिमेंटिक स्थान को सीमित करती है।
- Canonicalization नामों और संबंधों को सामान्य बनाता है।
- resolution_agent (या स्थानीय fuzzy शॉर्टकट) इकाई का समाधान करता है।
- policy_agent ऑन्टोलॉजिकल शोर से बचने के लिए सिमेंटिक गेट लागू करता है।
एडमिन चैटबॉट ग्राफ को कैसे नेविगेट करता है
एडमिन मोड में, सहायक ग्राफ को सुरक्षित रूप से एक्सप्लोर करने के लिए टूल्स का उपयोग करता है।
मुख्य टूल्स:
- describe_graph_schema
- find_entity
- neighbors
- shortest_path
- graph_stats
- recent_relations
- run_graph_query (केवल पठन)
उपयोग का उदाहरण:
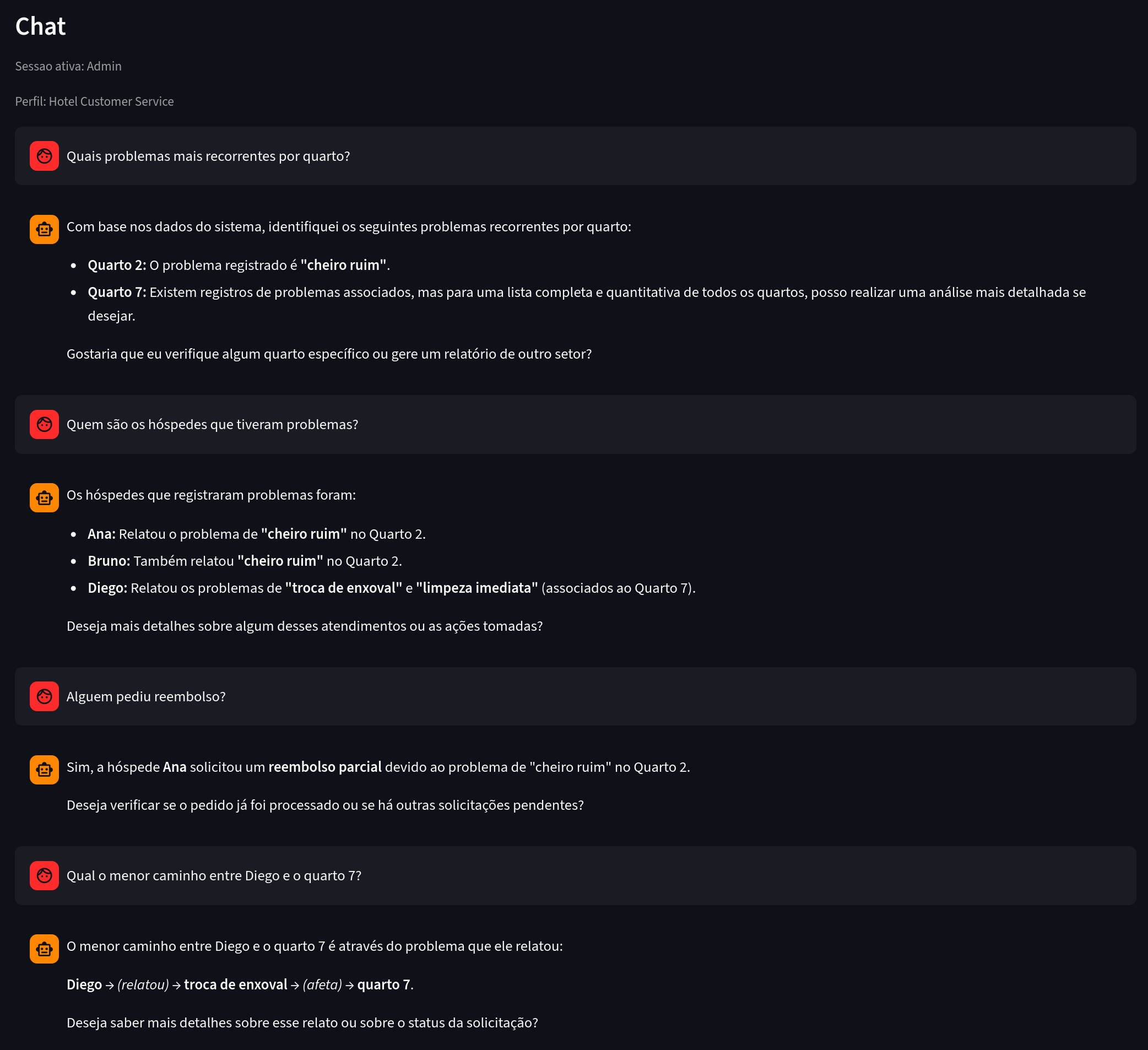
चित्र 8. ध्यान दें: स्पष्ट कनेक्शन के आधार पर उत्तर दिए गए विश्लेषणात्मक प्रश्न।
अन्य उद्योग जहाँ यह बहुत अच्छी तरह फिट बैठता है
ई-कॉमर्स
वही सिद्धांत, अलग डोमेन:
- उत्पाद में रुचि रखने वाला उपयोगकर्ता,
- प्रतिस्पर्धी से तुलना,
- डिलीवरी या भुगतान की समस्या,
- कार्रवाई का अनुरोध (बदलाव, रद्दीकरण, धनवापसी)।
सही प्रॉम्प्ट प्रोफाइल के साथ, आप मैप कर सकते हैं:
- सबसे अधिक खरीद इरादे वाले उत्पाद,
- सबसे अधिक उल्लिखित प्रतिस्पर्धी,
- प्रत्येक चरण में अनुभव की बाधाएँ,
- ग्राहक खंड के अनुसार पैटर्न।
अन्य स्वाभाविक परिदृश्य: SaaS सहायता, दूरसंचार, स्वास्थ्य, शिक्षा और वित्तीय सहायता।
सीख: डोमेन ज्ञान का महत्व
एक महत्वपूर्ण सीख यह रही: डोमेन संदर्भ के बिना, AI ऐसे कनेक्शन बना सकता है जो व्यवसाय के लिए मायने नहीं रखते।
यदि आप स्पष्ट रूप से नहीं बताते कि ग्राफ में किस प्रकार की चीजें होनी चाहिए, तो LLM मिला देता है:
- ठोस तथ्य (अच्छे), और
- प्रक्रिया कलाकृतियाँ या अस्पष्ट व्याख्याएँ (शोर)।
व्यवहार में Domain Policy
Domain policy आपके ग्राफ का सिमेंटिक अनुबंध है।
होटल में उदाहरण:
- User -> reported_issue -> Issue
- Issue -> affects_location -> Location
- User -> requested_action -> Activity
इससे पाइपलाइन पूर्वानुमानित हो जाती है और ग्राफ विश्लेषणात्मक क्वेरी के लिए बहुत अधिक उपयोगी हो जाता है।
यह AI को समझाता है कि आपके व्यवसाय के लिए कौन से संबंध मायने रखते हैं।
इकाई समाधान आज कैसे किया जाता है
आज हम एक हाइब्रिड और व्यावहारिक दृष्टिकोण का उपयोग करते हैं:
- नाम और प्रासंगिक टोकन द्वारा ग्राफ में उम्मीदवारों की खोज (find_entity)।
- स्ट्रिंग समानता और टोकन ओवरलैप को मिलाकर स्थानीय स्कोर।
- जब स्कोर प्रकार के अनुसार थ्रेशोल्ड पार करे तो मौजूदा इकाई का पुनः उपयोग।
- अधिक अस्पष्ट मामलों में, resolution_agent निर्णय लेने के लिए अतिरिक्त टूल्स का उपयोग करता है।
शुरुआत के लिए अच्छा काम करता है और संचालित करना सरल है।
वर्तमान सीमाएँ:
- शाब्दिक समानता पर काफी निर्भर,
- दूर के पर्यायवाची और पैराफ्रेज़ के साथ अधिक संघर्ष,
- इकाई प्रकार के अनुसार थ्रेशोल्ड के सूक्ष्म समायोजन की आवश्यकता।
भविष्य के सुधार: इकाइयों और संबंधों को हल करने के लिए Embeddings
एक स्वाभाविक विकास embeddings के साथ सिमेंटिक समाधान जोड़ना है।
आर्किटेक्चर का विचार:
- उम्मीदवार इकाइयों और नए उल्लेखों के लिए embedding उत्पन्न करें।
- वेक्टर इंडेक्स में निकटतम पड़ोसियों की खोज करें।
- डोमेन नियमों (इकाई प्रकार, स्थानीय संदर्भ और मौजूदा संबंध) के साथ पुनः रैंक करें।
- कैलिब्रेटेड विश्वास के साथ मर्ज या पुनः उपयोग की पुष्टि करें।
अपेक्षित लाभ:
- पर्यायवाची और भाषाई विविधताओं का बेहतर उपचार,
- कम सिमेंटिक दोहराव,
- स्ट्रिंग मिलान हेयुरिस्टिक्स पर कम निर्भरता।
भविष्य का विस्तार: संभावित संबंधों का सुझाव देने के लिए भी embeddings का उपयोग करें, हमेशा संरचनात्मक मतिभ्रम से बचने के लिए policy gate के साथ।
निष्कर्ष
मुख्य बात केवल एक ऐसा चैटबॉट होना नहीं है जो अच्छी तरह उत्तर दे।
असली अंतर बातचीत को सिमेंटिक गुणवत्ता और ट्रेसेबिलिटी के साथ क्वेरी योग्य संरचना में बदलने में है।
होटल के मामले में, इसका अर्थ है:
- स्थान के अनुसार पुनरावृत्ति देखना,
- मेहमान के अनुभव को परिचालन प्रभाव से जोड़ना,
- ग्राफ में साक्ष्य के साथ विश्लेषणात्मक प्रश्नों का उत्तर देना।
संक्षेप में: पाठ्य स्मृति मदद करती है। संरचित स्मृति उन व्यावसायिक अंतर्दृष्टियों को सक्षम बनाती है जो पहल�े प्राप्त करना कठिन था।
Tags: #chatbot #ज्ञानग्राफ #knowledgeGraph #Neo4j #कृत्रिमबुद्धिमत्ता #LLM #NLP #सूचनाएक्सट्रैक्शन #सिमेंटिकट्रिपल्स #डेटाविश्लेषण #उत्पादअंतर्दृष्टि #ग्राहकसेवा #डेटाआर्किटेक्चर #RAG #सिमेंटिक्स #प्राकृतिकभाषाप्रसंस्करण #संरचितडेटा #इकाईसमाधान #embeddings #businessIntelligence