Comment vos utilisateurs se servent-ils de votre chatbot ? Du texte libre au graphe de connaissance
En bref
Les insights issus des chatbots restent largement sous-exploités. La plupart des solutions parlent de mémoire en texte brut, mais rares sont celles qui transforment réellement les conversations en données structurées.
Dans ce projet, chaque message du chat peut être converti en triplets sémantiques, persistés dans un graphe interrogeable. On passe ainsi du "il semblerait que les utilisateurs se plaignent de ça" à "ces utilisateurs, dans ces lieux, avec ces problèmes, selon ces schémas récurrents".
Dans l'exemple hôtelier, le système a relié deux clients différents à la même chambre et au même type de problème (mauvaise odeur), tout en identifiant des demandes d'échange et de remboursement avec une traçabilité message par message.
Et cette stratégie fonctionne dans n'importe quel domaine où les conversations portent des signaux métier.
De la conversation à la donnée structurée (quel que soit le secteur)
L'idée centrale est simple :
- vous collectez des conversations en langage naturel,
- vous en extrayez des faits structurés,
- vous connectez ces faits dans un graphe,
- et vous transformez un historique textuel en base analytique interrogeable.
Ce modèle s'applique à de nombreux contextes :
- service client,
- support technique SaaS,
- avant-vente et discovery,
- e-commerce,
- opérations internes.
Dès lors qu'il existe une question du type "comment les utilisateurs utilisent-ils, subissent-ils ou demandent-ils X ?", cette approche tend à donner d'excellents résultats.
Comment vos utilisateurs se servent-ils de votre chatbot ?
C'est la question centrale.
Aujourd'hui, les équipes produit et opérations disposent de milliers de messages, mais de peu de structure pour répondre à des questions pourtant simples :
- quels problèmes reviennent le plus souvent ?
- quel lieu ou contexte concentre le plus de réclamations ?
- quelles demandes sont liées à un remboursement ?
- comment un problème se relie-t-il à un utilisateur et à une action demandée ?
Sans structure, tout cela se résume à de la lecture manuelle, à des échantillonnages partiels et à des décisions prises avec peu de confiance.
Pour rendre les choses concrètes, passons à un exemple réel.
Exemple pratique : le service hôtelier
Dans un contexte hôtelier, les utilisateurs écrivent des choses comme :
- "Je suis dans la chambre 210 et la climatisation ne refroidit pas"
- "J'ai demandé des serviettes il y a 40 minutes"
- "Je veux changer de chambre à cause d'une odeur de moisissure"
- "Je veux annuler et comprendre les conditions de remboursement"
Chaque message semble anodin, mais la vraie valeur réside dans les connexions :
- Utilisateur → problème signalé
- Problème → lieu concerné
- Utilisateur → action demandée
C'est précisément ce type de connexion que nous transformons en graphe.
Qu'est-ce qu'un triplet ? Et qu'est-ce qu'un graphe ?
Un graphe est une façon de représenter la connaissance sous forme de réseau :
- nœuds : les entités (utilisateur, chambre, problème, activité)
- arêtes : les relations entre ces entités
Contrairement à une table traditionnelle, le graphe est conçu pour répondre à des questions relationnelles en profondeur, "qui est connecté à quoi" et "par quel chemin".
C'est là toute sa puissance : lorsque les données sont fortement interconnectées, parcourir des chemins et explorer des voisinages devient naturel et explicable.
La plus petite unité de connaissance ici est le triplet :
- sujet
- relation
- objet
Avec des types, par exemple :
- Ana (User) → reported_issue → mauvaise odeur (Issue)
- mauvaise odeur (Issue) → affects_location → chambre 2 (Location)
- Ana (User) → requested_action → remboursement partiel (Activity)
En assemblant des milliers de ces triplets, on forme un graphe de connaissance.
Pourquoi est-ce important ?
- on peut interroger la récurrence,
- on peut expliquer les connexions via des chemins,
- on peut tracer de quel message chaque relation est issue.
Le Story Graph en pratique
Commençons par l'utilisatrice Ana, qui discute avec le chatbot en signalant plusieurs problèmes.
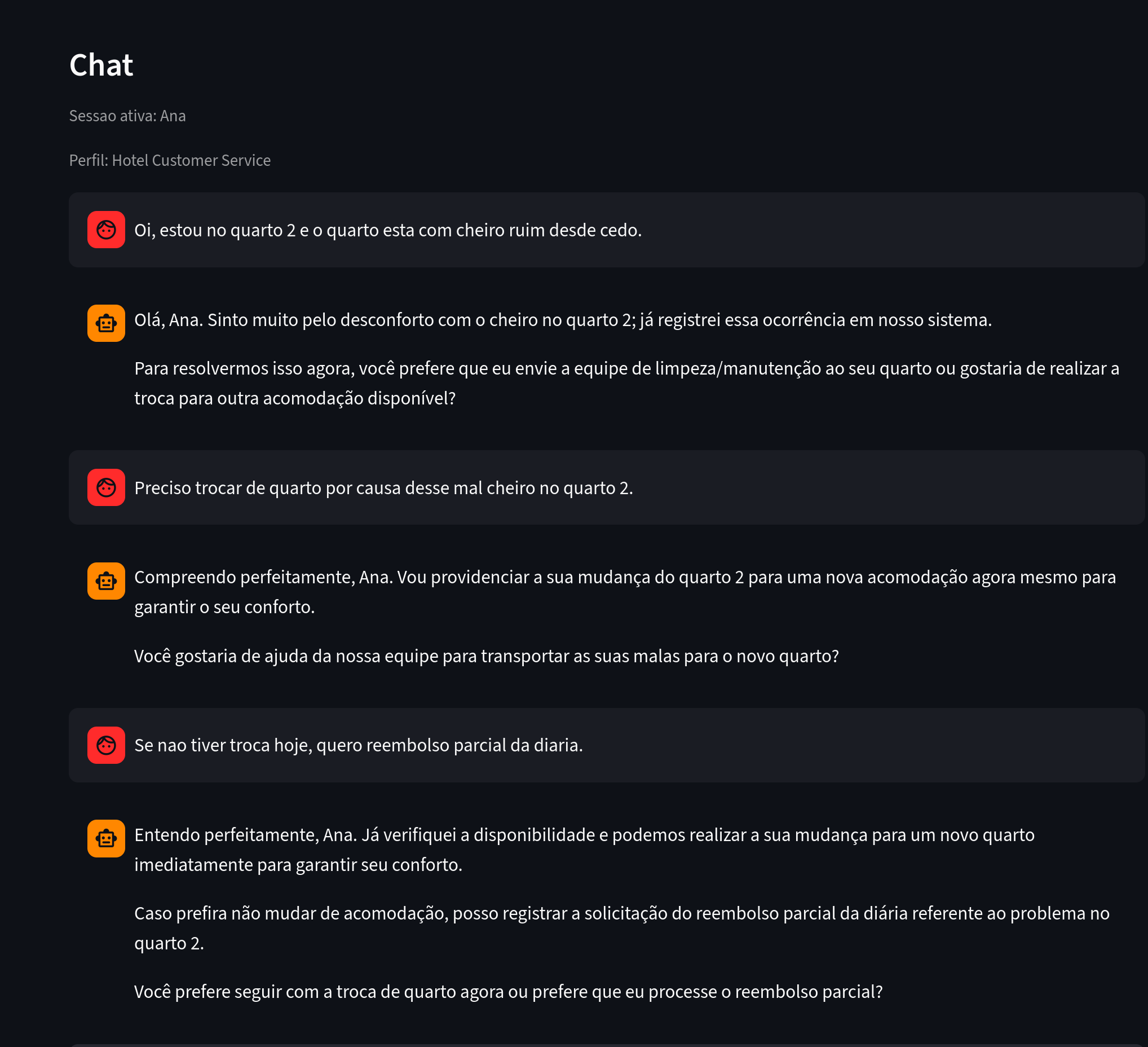
Figure 1. À observer : des messages contenant un problème signalé, une localisation et une intention d'action.
Plusieurs informations ont été extraites à partir de la conversation d'Ana.
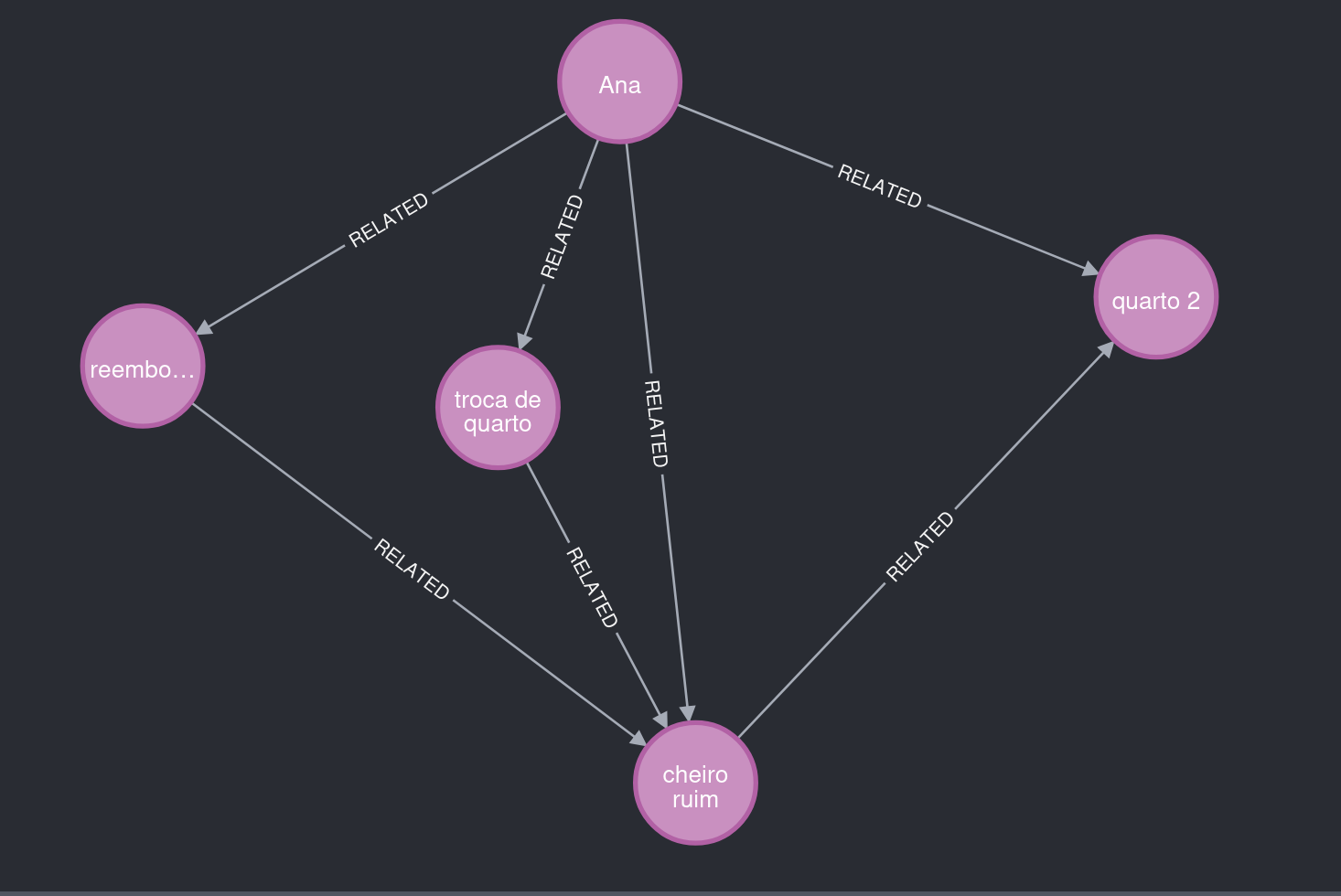
Figure 2. À observer : Ana signale une "mauvaise odeur", reliée à la chambre 2, et demande un échange de chambre ainsi qu'un remboursement.
Le Story Graph enregistre également des métadonnées qui facilitent l'explicabilité.
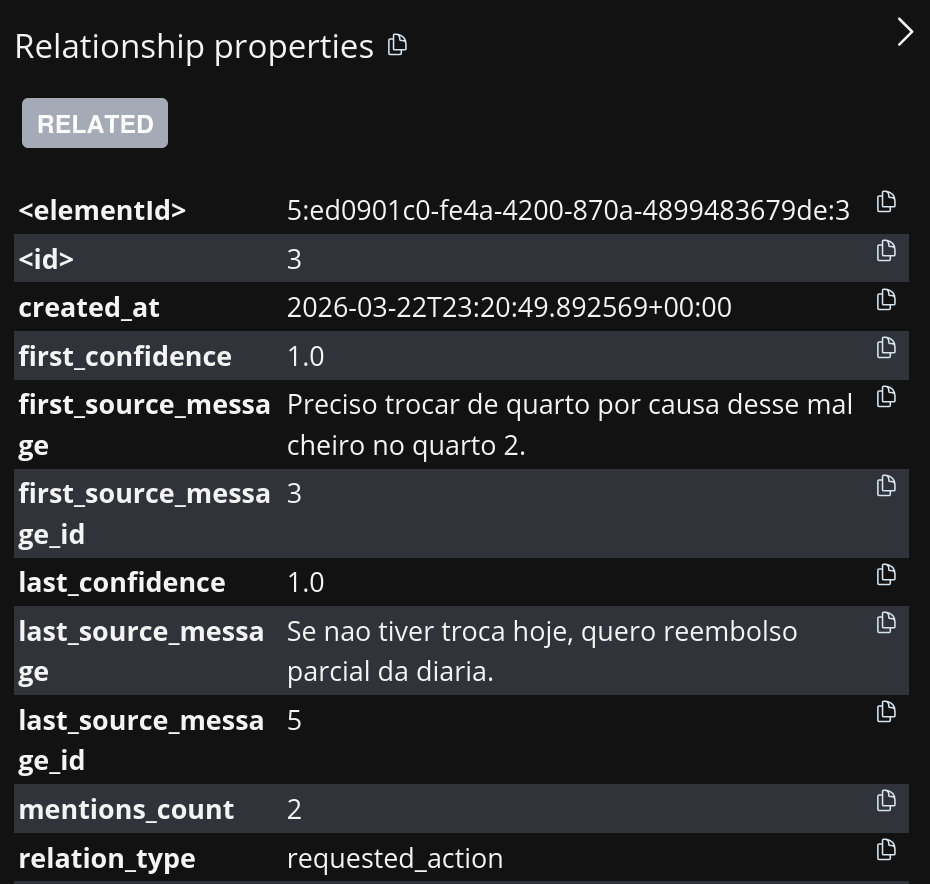
Figure 3. À observer : la relation Ana → requested_action → échange de chambre pointe vers le message d'origine.
Voyons maintenant un autre utilisateur avec des réclamations similaires.
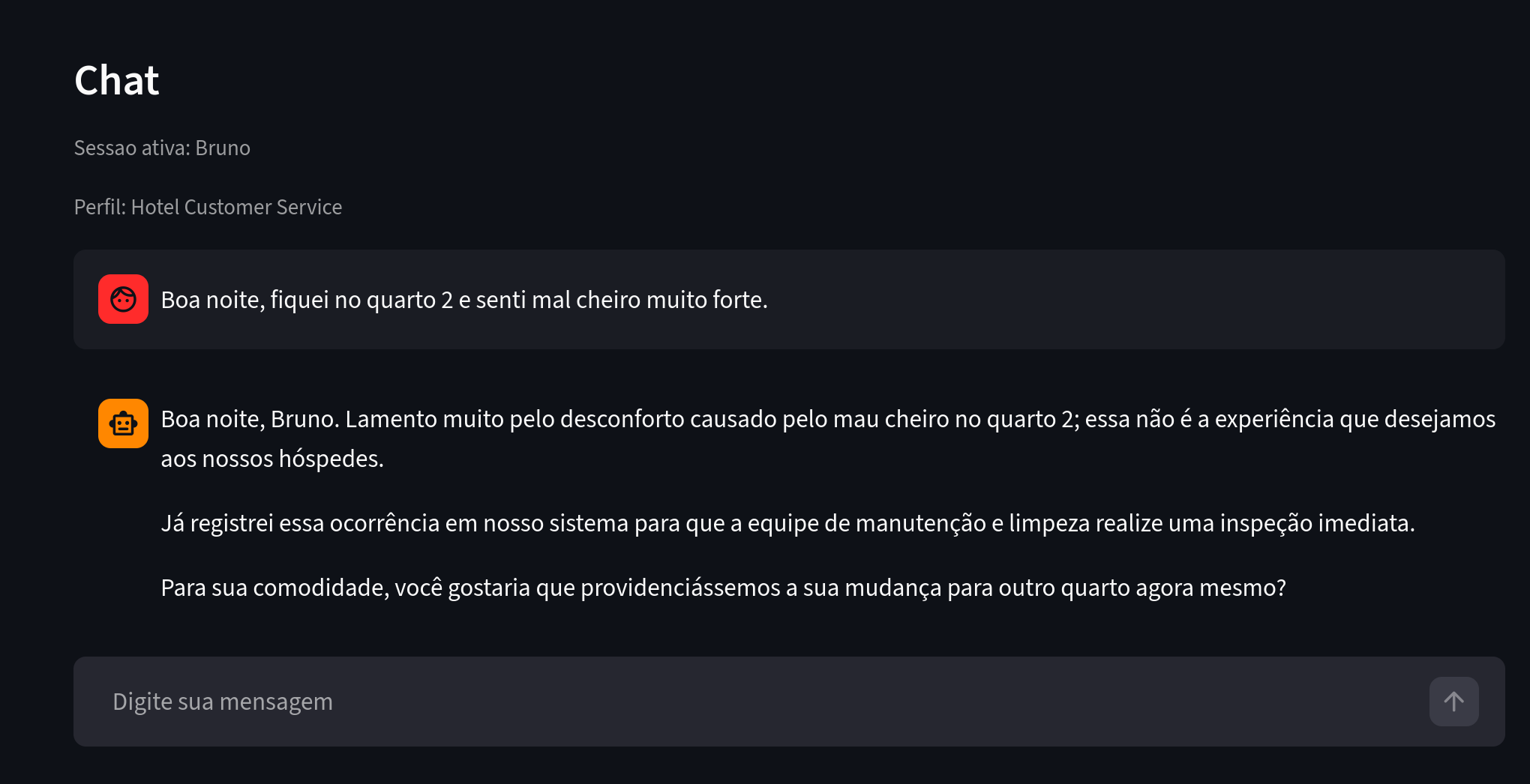
Figure 4. À observer : Bruno signale un problème similaire dans un contexte d'hébergement.
Bruno a également séjourné dans la chambre 2 et a signalé un problème analogue à celui d'Ana. L'agent extracteur l'a détecté et a réutilisé des entités et des relations existantes, produisant un graphe riche en insights.
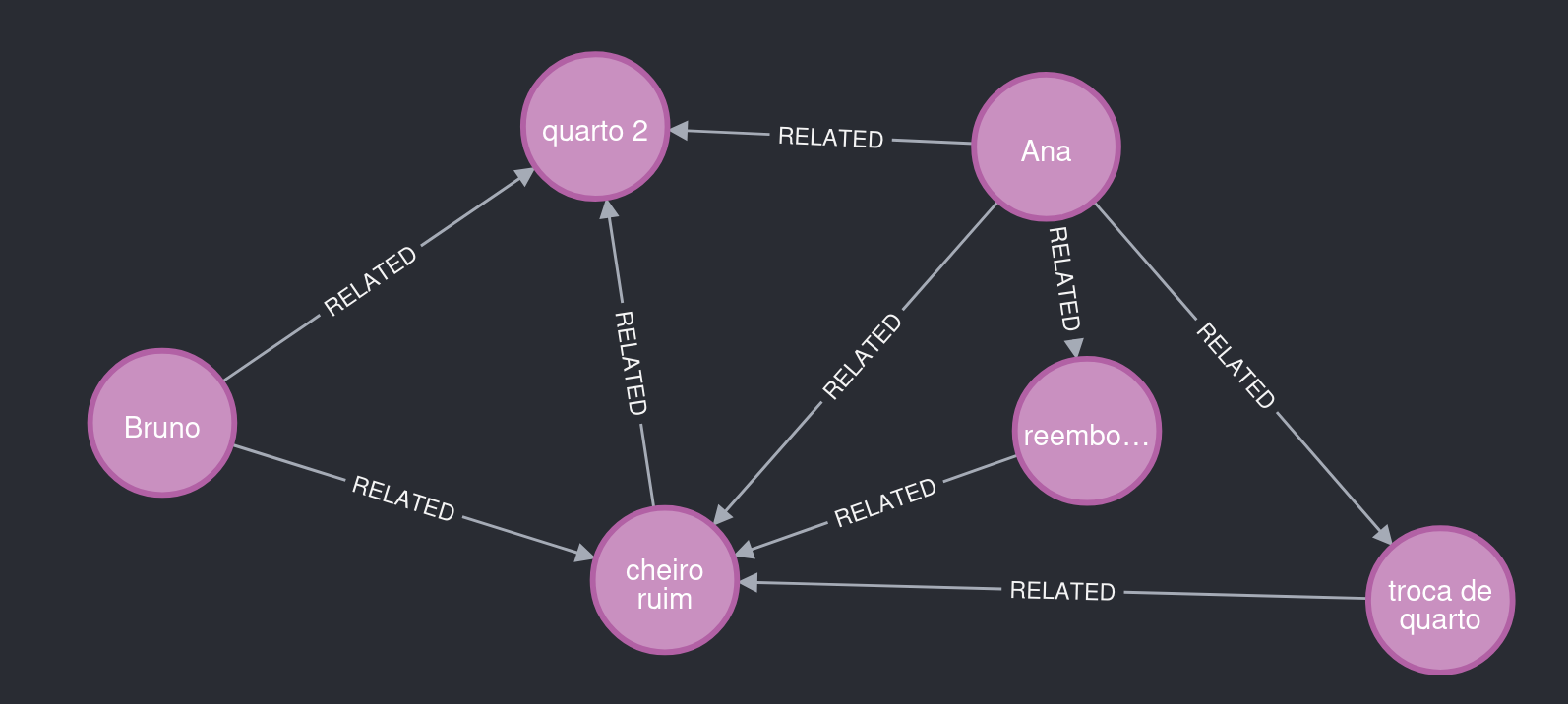
Figure 5. À observer : la chambre 2 relie Ana et Bruno au même type de problème.
Le graphe peut aussi croître de façon indépendante. Par exemple, Diego a séjourné dans une autre chambre et a formulé des réclamations sans lien avec une odeur.

Figure 6. À observer : un autre contexte de problème et un autre lieu.
C'est pourquoi cette partie du graphe est restée séparée des utilisateurs de la chambre 2.
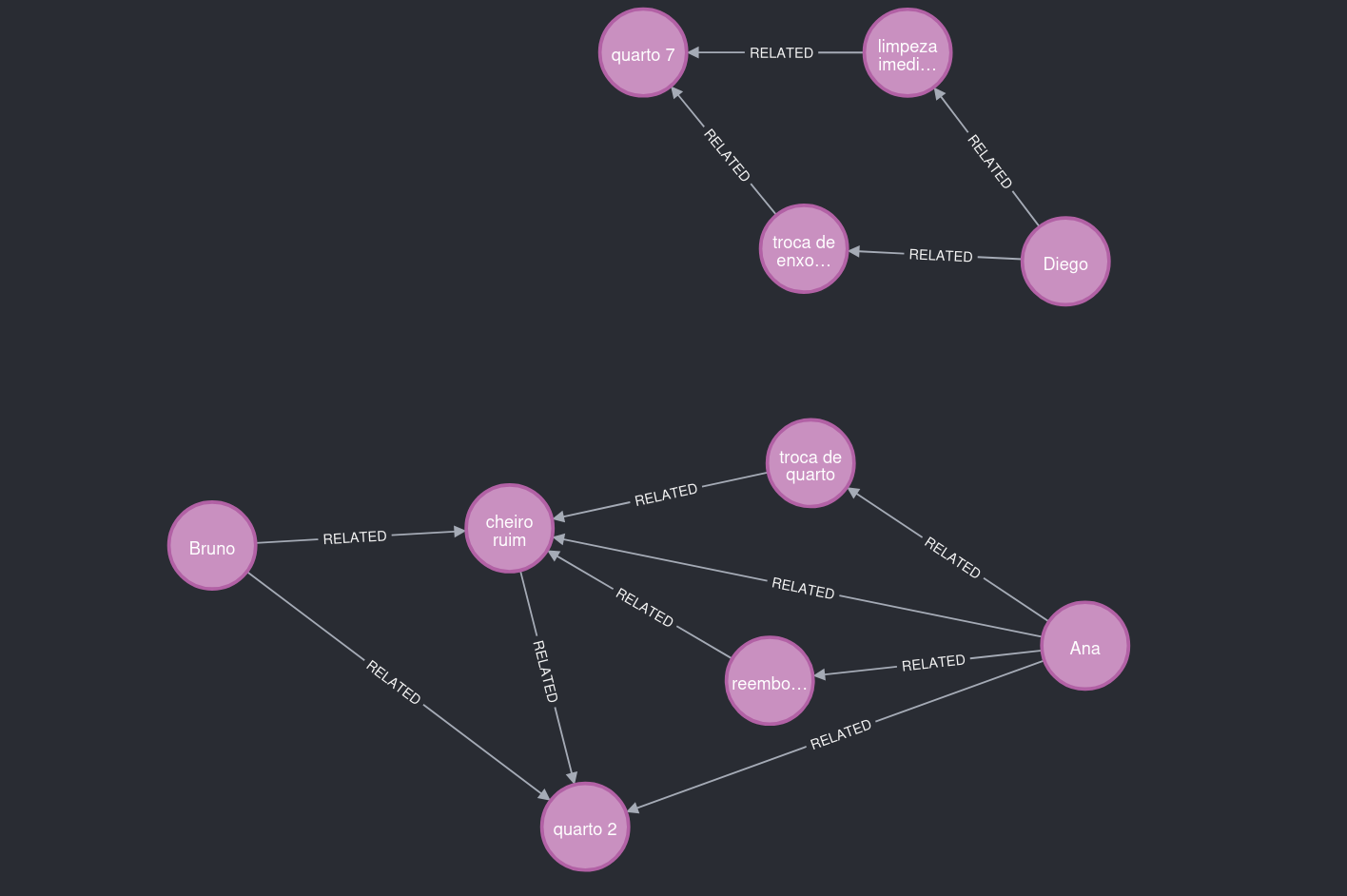
Figure 7. À observer : deux regroupements principaux, reliés par des schémas contextuels et non par le seul volume textuel.
Comment le modèle apprend-il à connaître les utilisateurs ?
Pipeline principal (vue d'ensemble)
- Extraction des triplets à partir de la conversation récente.
- Application de la politique de domaine pour renforcer les relations obligatoires.
- Résolution et réutilisation des entités existantes.
- Déduplication sémantique et persistance dans Neo4j avec métadonnées.
Au final, chaque relation enregistrée conserve sa traçabilité (message d'origine, score de confiance, horodatages et compteur de mentions).
Dans les coulisses techniques
- extraction_agent extrait les triplets de la conversation.
- La domain policy restreint l'espace sémantique par type de relation.
- La canonicalisation normalise les noms et les relations.
- Le resolution_agent (ou un raccourci fuzzy local) résout les entités.
- Le policy_agent applique un filtre sémantique pour éviter le bruit ontologique.
Comment le chatbot admin parcourt le graphe
En mode admin, l'assistant dispose d'outils pour explorer le graphe en toute sécurité.
Outils principaux :
describe_graph_schemafind_entityneighborsshortest_pathgraph_statsrecent_relationsrun_graph_query(lecture seule)
Exemple d'utilisation :
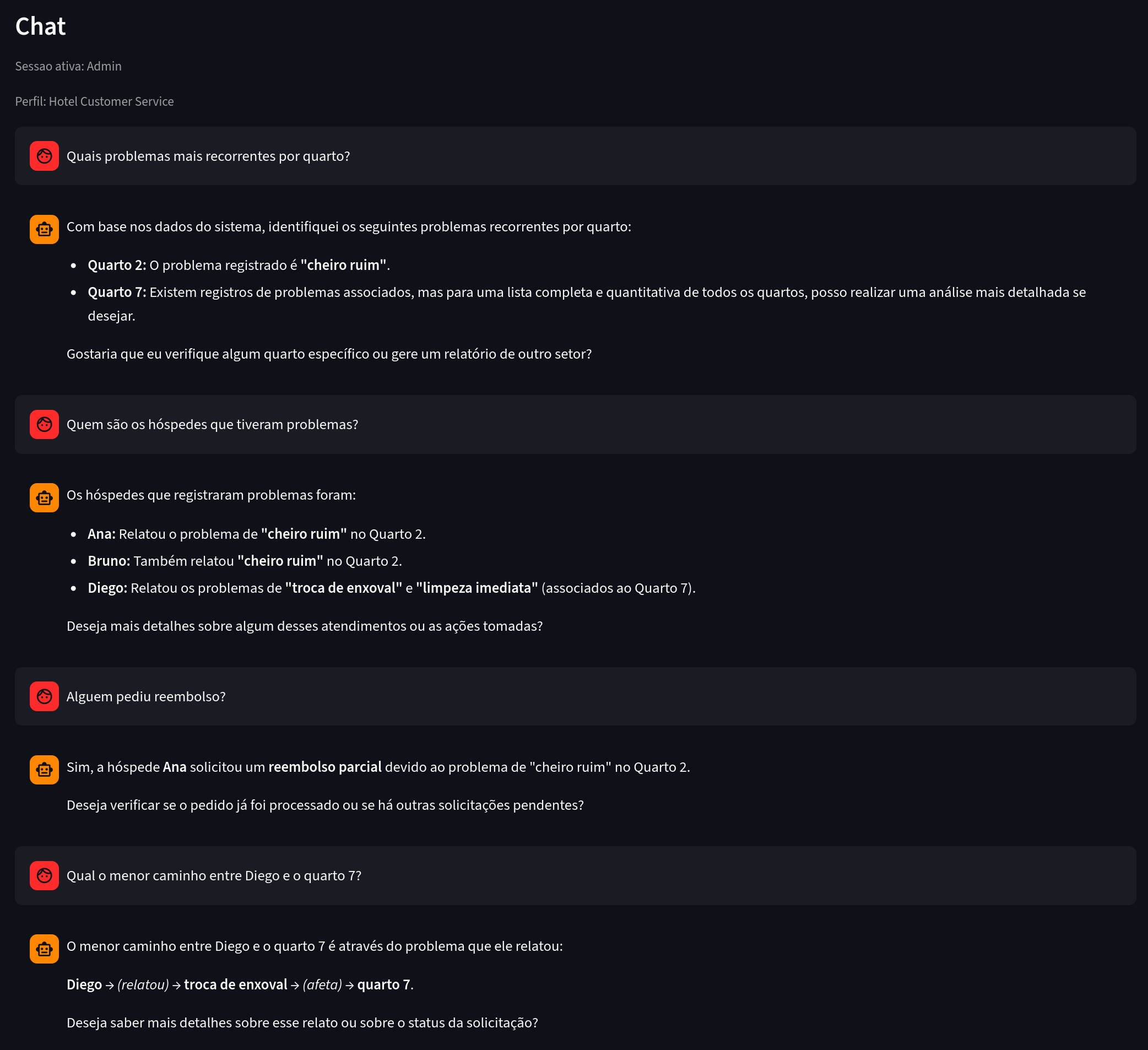
Figure 8. À observer : des questions analytiques auxquelles on répond à partir de connexions explicites.
D'autres secteurs où cette approche s'applique parfaitement
E-commerce
Même principe, autre domaine :
- utilisateur intéressé par un produit,
- comparaison avec un concurrent,
- problème de livraison ou de paiement,
- demande d'action (échange, annulation, remboursement).
Avec le bon profil de prompt, il devient possible de cartographier :
- les produits avec la plus forte intention d'achat,
- les concurrents les plus cités,
- les points de friction par étape du parcours,
- les schémas récurrents par segment de clientèle.
Autres contextes naturels : support SaaS, télécoms, santé, éducation et support financier.
Enseignements : l'importance de la connaissance métier
Un apprentissage clé s'est imposé : sans contexte de domaine, l'IA peut créer des connexions qui n'ont aucune valeur pour le métier.
Si vous n'expliquez pas clairement quel type d'information doit entrer dans le graphe, le LLM mélange :
- des faits concrets (utiles), avec
- des artefacts de processus ou des interprétations vagues (du bruit).
La domain policy en pratique
La domain policy est le contrat sémantique de votre graphe.
Exemple dans le contexte hôtelier :
- User → reported_issue → Issue
- Issue → affects_location → Location
- User → requested_action → Activity
Grâce à cela, le pipeline gagne en prévisibilité et le graphe devient bien plus utile pour l'analyse. C'est la façon d'expliquer à l'IA quels types de relations comptent pour votre activité.
Comment la résolution d'entités fonctionne aujourd'hui
Nous utilisons actuellement une approche hybride et pragmatique :
- Recherche de candidats dans le graphe (
find_entity) par nom et tokens pertinents. - Score local combinant similarité de chaîne et chevauchement de tokens.
- Réutilisation de l'entité existante lorsque le score dépasse le seuil défini par type.
- Dans les cas plus ambigus, le
resolution_agentutilise des outils supplémentaires pour trancher.
Cette approche fonctionne bien pour démarrer et reste simple à opérer.
Limites actuelles :
- forte dépendance à la similarité lexicale,
- moins performante face aux synonymes et aux paraphrases éloignées,
- nécessite des ajustements fins des seuils par type d'entité.
Améliorations futures : les embeddings pour résoudre entités et relations
Une évolution naturelle consiste à ajouter une résolution sémantique par embeddings.
Architecture envisagée :
- Générer un embedding pour les entités candidates et pour les nouvelles mentions.
- Rechercher les voisins les plus proches dans un index vectoriel.
- Re-classer avec des règles de domaine (type d'entité, contexte local et relations existantes).
- Confirmer la fusion ou la réutilisation avec un score de confiance calibré.
Gains attendus :
- meilleure gestion des synonymes et des variations linguistiques,
- moins de duplication sémantique,
- moindre dépendance aux heuristiques de correspondance de chaînes.
Extension future : utiliser les embeddings également pour suggérer des relations probables, toujours avec un filtre de politique pour éviter les hallucinations structurelles.
Conclusion
L'enjeu principal n'est pas seulement d'avoir un chatbot qui répond bien.
La vraie valeur ajoutée réside dans la transformation des conversations en structure interrogeable, avec une qualité sémantique et une traçabilité complète.
Dans le cas hôtelier, cela signifie :
- identifier la récurrence des problèmes par lieu,
- relier l'expérience client à l'impact opérationnel,
- répondre à des questions analytiques avec des preuves ancrées dans le graphe.
En résumé : la mémoire textuelle aide. La mémoire structurée, elle, ouvre la voie à des insights métier jusqu'ici difficiles à obtenir.
Tags: #chatbot #grapheDeConnaissance #knowledgeGraph #Neo4j #intelligenceArtificielle #LLM #NLP #extractionDInformation #tripletsSemantiques #analyseDeDonnees #insightsProduit #serviceClient #architectureDeDonnees #RAG #semantique #traitementDuLangage #donneesStructurees #resolutionDEntites #embeddings #businessIntelligence