¿Cómo usan tus usuarios tu chatbot? Del texto libre al grafo de conocimiento
TL;DR
Los insights extraídos de chatbots siguen siendo un recurso poco aprovechado. La mayoría de las soluciones habla de memoria en texto plano, pero casi ninguna transforma las conversaciones en datos estructurados.
En este proyecto, cada mensaje del chat puede convertirse en tripletas semánticas, persistidas en un grafo consultable. Con eso, pasamos del "parece que los usuarios se quejan de esto" a "estos usuarios, en estos lugares, con estos problemas, siguiendo estos patrones".
En el ejemplo del hotel, el sistema conectó a dos huéspedes distintos con la misma habitación y el mismo tipo de problema (mal olor), además de identificar solicitudes de cambio y reembolso con trazabilidad por mensaje.
Y esta estrategia funciona para cualquier dominio en el que las conversaciones lleven señales de negocio.
De conversación a dato estructurado (independientemente del sector)
La idea central es sencilla:
- recopilas conversaciones en lenguaje natural,
- extraes hechos estructurados,
- conectas esos hechos en un grafo,
- y transformas el historial textual en una base analítica consultable.
Este modelo puede aplicarse en múltiples escenarios:
- atención al cliente,
- soporte técnico SaaS,
- preventa y discovery,
- e-commerce,
- operaciones internas.
Siempre que exista una pregunta del tipo "¿cómo están usando, sufriendo o pidiendo X los usuarios?", este enfoque tiende a funcionar muy bien.
¿Cómo usan tus usuarios tu chatbot?
Esa es la pregunta clave.
Hoy en día, los equipos de producto y operaciones manejan miles de mensajes, pero cuentan con poca estructura para responder preguntas simples:
- ¿qué problemas aparecen con más frecuencia?
- ¿qué lugar o contexto concentra más quejas?
- ¿qué solicitudes están relacionadas con reembolsos?
- ¿cómo se conecta un problema con un usuario y con una acción solicitada?
Sin estructura, todo se convierte en lectura manual, muestreo parcial y decisiones con baja confianza.
Para hacerlo concreto, veamos un ejemplo real.
Ejemplo práctico: atención en un hotel
En el escenario hotelero, el usuario escribe cosas como:
- "Estoy en la habitación 210 y el aire acondicionado no enfría"
- "Pedí toallas hace 40 minutos y no han llegado"
- "Quiero cambiar de habitación por olor a humedad"
- "Quiero cancelar y saber cómo funciona el reembolso"
Cada mensaje parece simple, pero el valor real está en las conexiones:
- Usuario -> problema reportado
- Problema -> ubicación afectada
- Usuario -> acción solicitada
Es exactamente ese tipo de conexión lo que transformamos en grafo.
¿Qué es una tripleta? ¿Y qué es un grafo?
Un grafo es una forma de representar conocimiento como una red:
- nodos: las entidades (usuario, habitación, problema, actividad)
- aristas: las relaciones entre esas entidades
A diferencia de una tabla tradicional, el grafo está diseñado para responder preguntas relacionales con profundidad, como "quién está conectado con qué" y "por qué camino".
Por eso es tan poderoso: cuando los datos están altamente conectados, consultar caminos y vecindades se vuelve algo natural y explicable.
La unidad mínima de conocimiento aquí es la tripleta:
- sujeto
- relación
- objeto
Con tipos, por ejemplo:
- Ana (User) -> reported_issue -> mal olor (Issue)
- mal olor (Issue) -> affects_location -> habitación 2 (Location)
- Ana (User) -> requested_action -> reembolso parcial (Activity)
Cuando juntamos miles de estas tripletas, formamos un grafo de conocimiento.
¿Por qué importa?
- se puede consultar la recurrencia,
- se pueden explicar conexiones a través de caminos,
- se puede rastrear de qué mensaje proviene cada relación.
Story Graph en la práctica
Empecemos por la usuaria Ana, que conversa con el chatbot y trae algunas quejas.
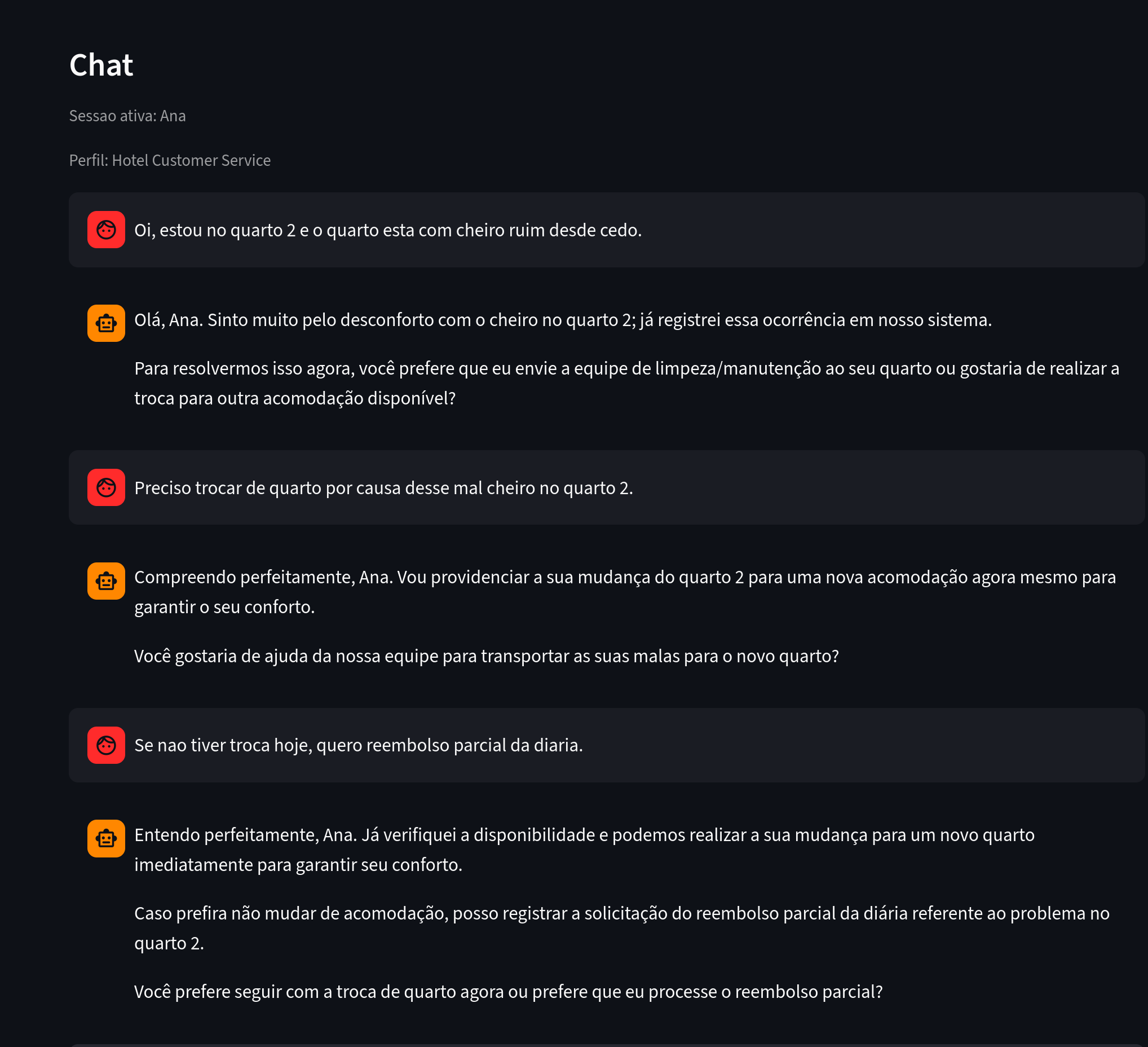
Figura 1. Qué observar: mensajes con problema reportado, ubicación e intención de acción.
A partir de ese chat se extrajeron varios datos sobre Ana.
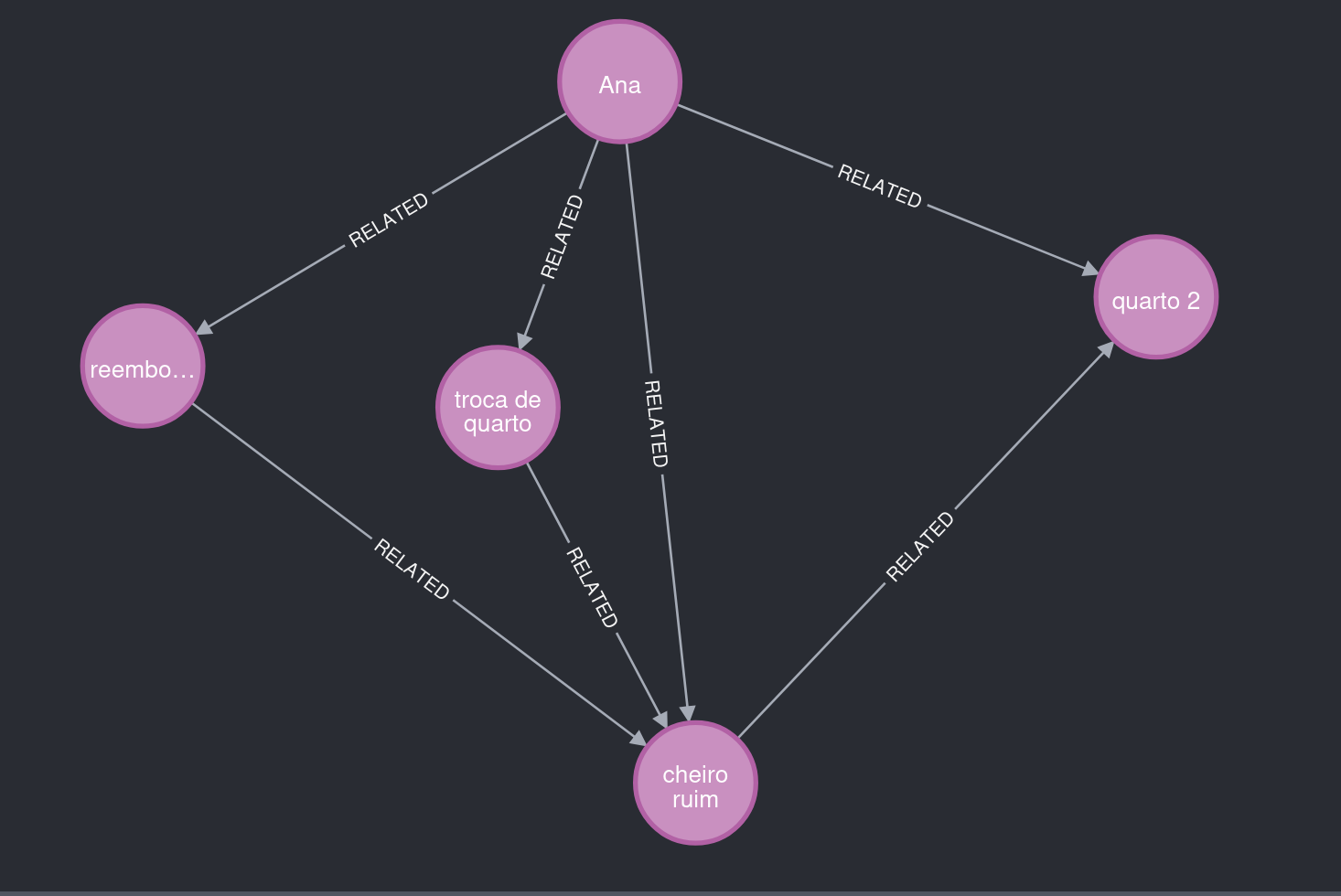
Figura 2. Qué observar: Ana reporta "mal olor", vinculado a la habitación 2, y solicita cambio de habitación y reembolso.
El Story Graph también guarda metadatos que ayudan a la explicabilidad.
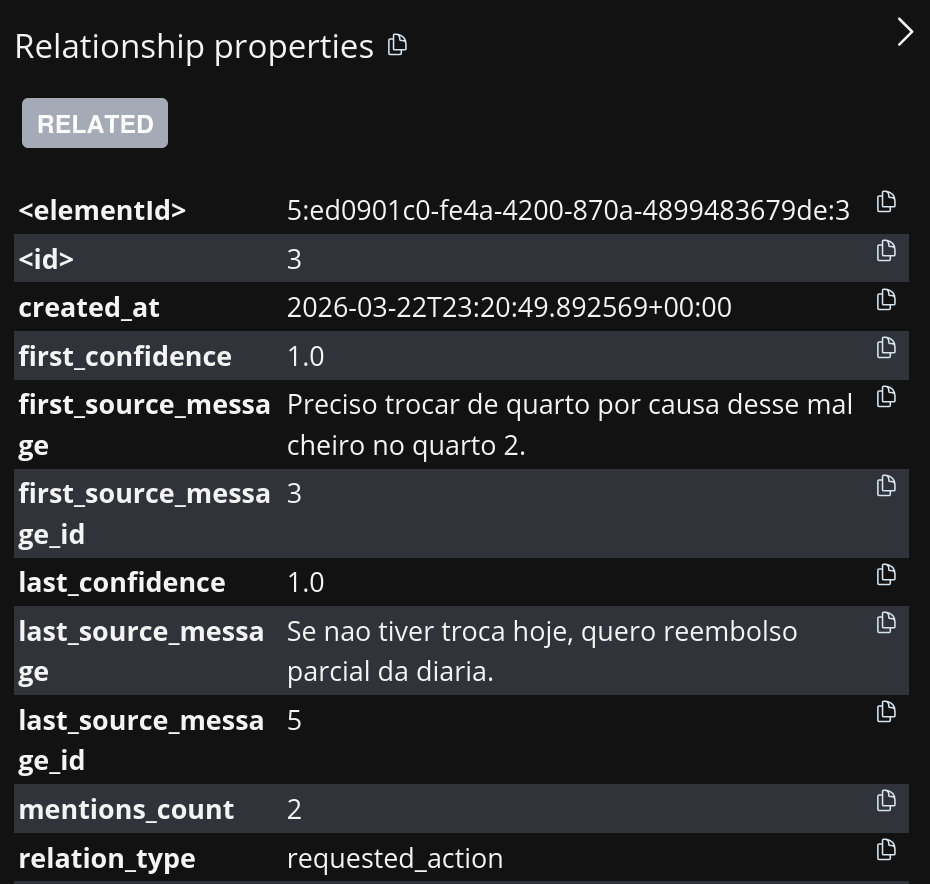
Figura 3. Qué observar: la relación Ana -> requested_action -> cambio de habitación apunta al mensaje de origen.
Ahora veamos a otro usuario con quejas similares.
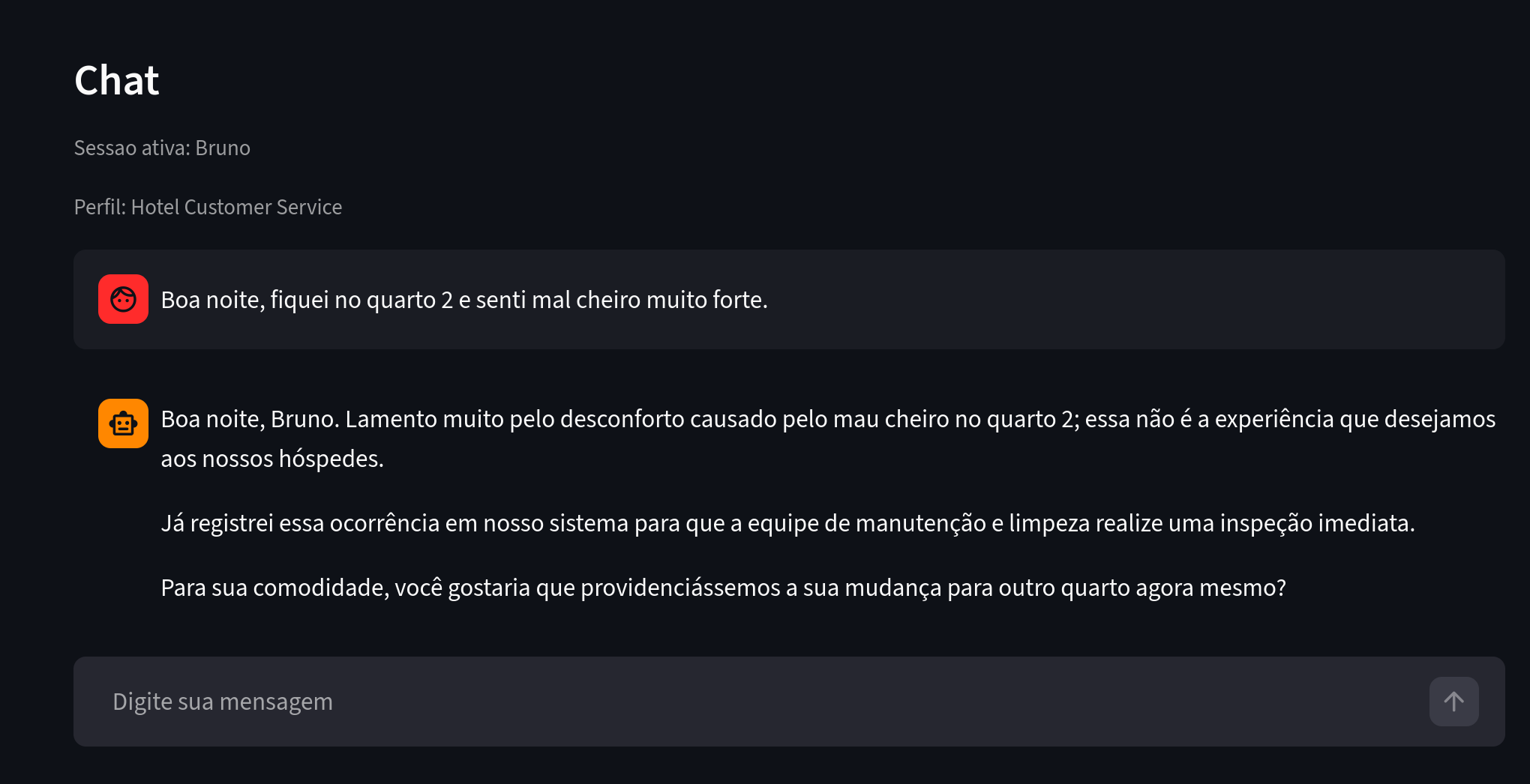
Figura 4. Qué observar: Bruno reporta un problema similar en un contexto de hospedaje.
Bruno también estuvo en la habitación 2 y reportó un problema parecido al de Ana. El agente extractor lo detectó y reutilizó entidades y relaciones, generando un grafo con insights interesantes.
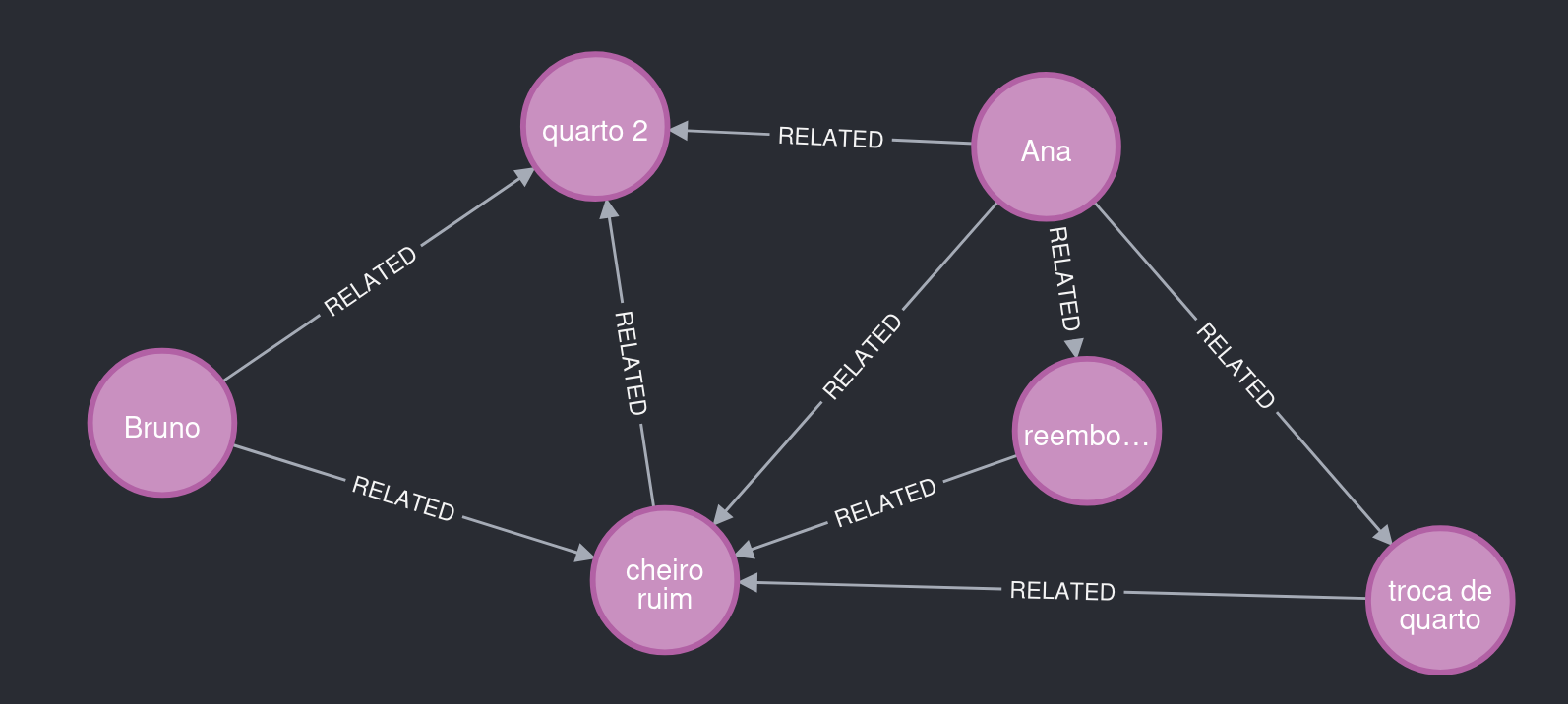
Figura 5. Qué observar: la habitación 2 conecta a Ana y Bruno con el mismo tipo de problema.
El grafo también puede crecer de forma independiente. Por ejemplo, Diego estuvo en otra habitación y presentó quejas no relacionadas con el olor.

Figura 6. Qué observar: otro contexto de problema y otra ubicación.
Por eso, esta parte del grafo quedó separada de los usuarios de la habitación 2.
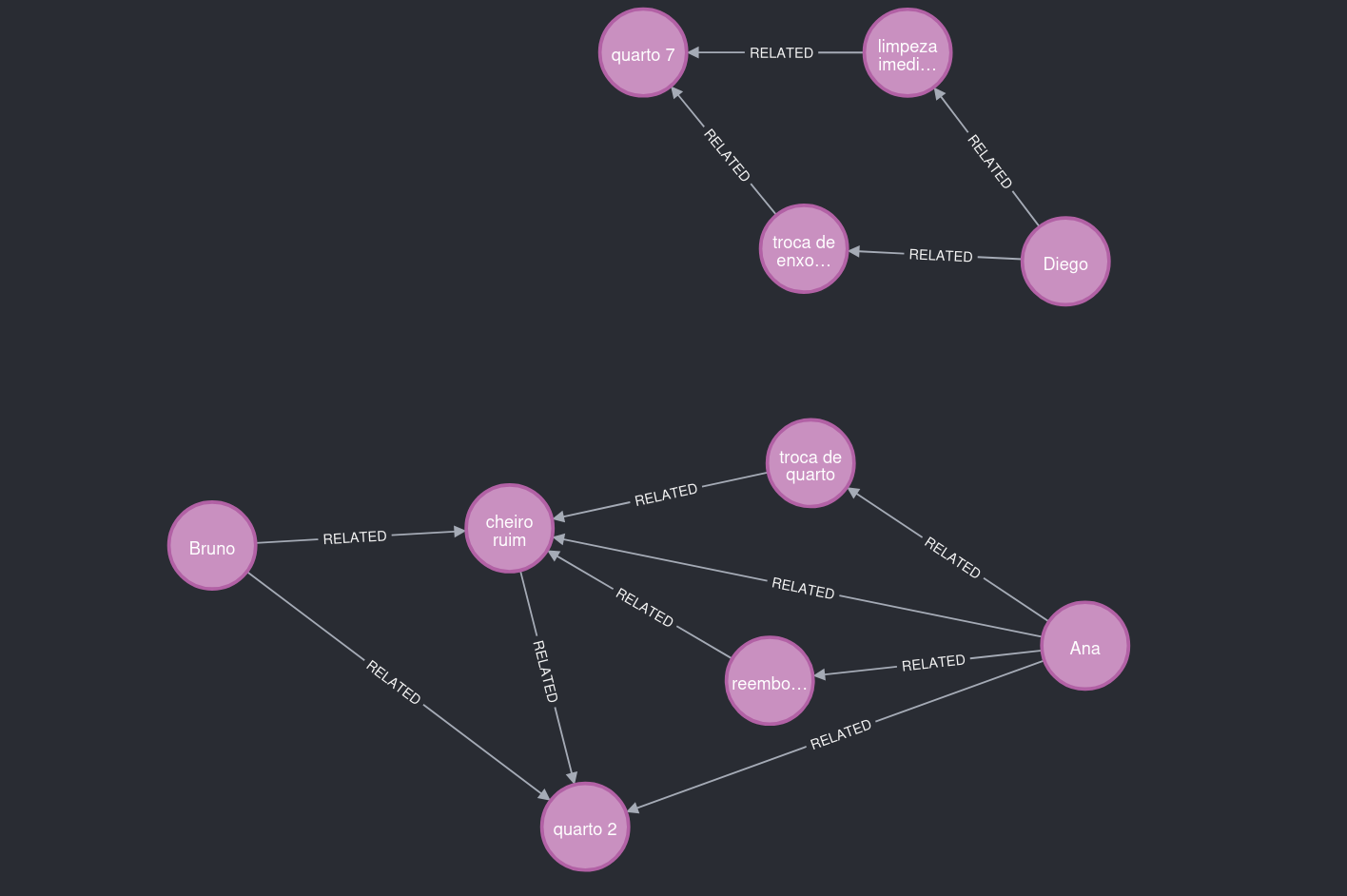
Figura 7. Qué observar: dos agrupaciones principales, conectadas por patrones de contexto y no solo por volumen textual.
¿Cómo aprende el modelo sobre los usuarios?
Pipeline principal (visión ejecutiva)
- Extracción de tripletas de la conversación reciente.
- Aplicación de política de dominio para reforzar relaciones obligatorias.
- Resolución y reutilización de entidades existentes.
- Deduplicación semántica y persistencia en Neo4j con metadatos.
Al final, cada relación guardada incluye trazabilidad (mensaje de origen, nivel de confianza, timestamps y contador de menciones).
Detalles técnicos
- extraction_agent extrae tripletas de la conversación.
- Domain policy restringe el espacio semántico por tipo de relación.
- Canonicalización normaliza nombres y relaciones.
- resolution_agent (o atajo fuzzy local) resuelve entidades.
- policy_agent aplica un filtro semántico para evitar ruido ontológico.
Cómo el chatbot admin navega el grafo
En el modo admin, el asistente utiliza herramientas para explorar el grafo de forma segura.
Herramientas principales:
- describe_graph_schema
- find_entity
- neighbors
- shortest_path
- graph_stats
- recent_relations
- run_graph_query (solo lectura)
Ejemplo de uso:
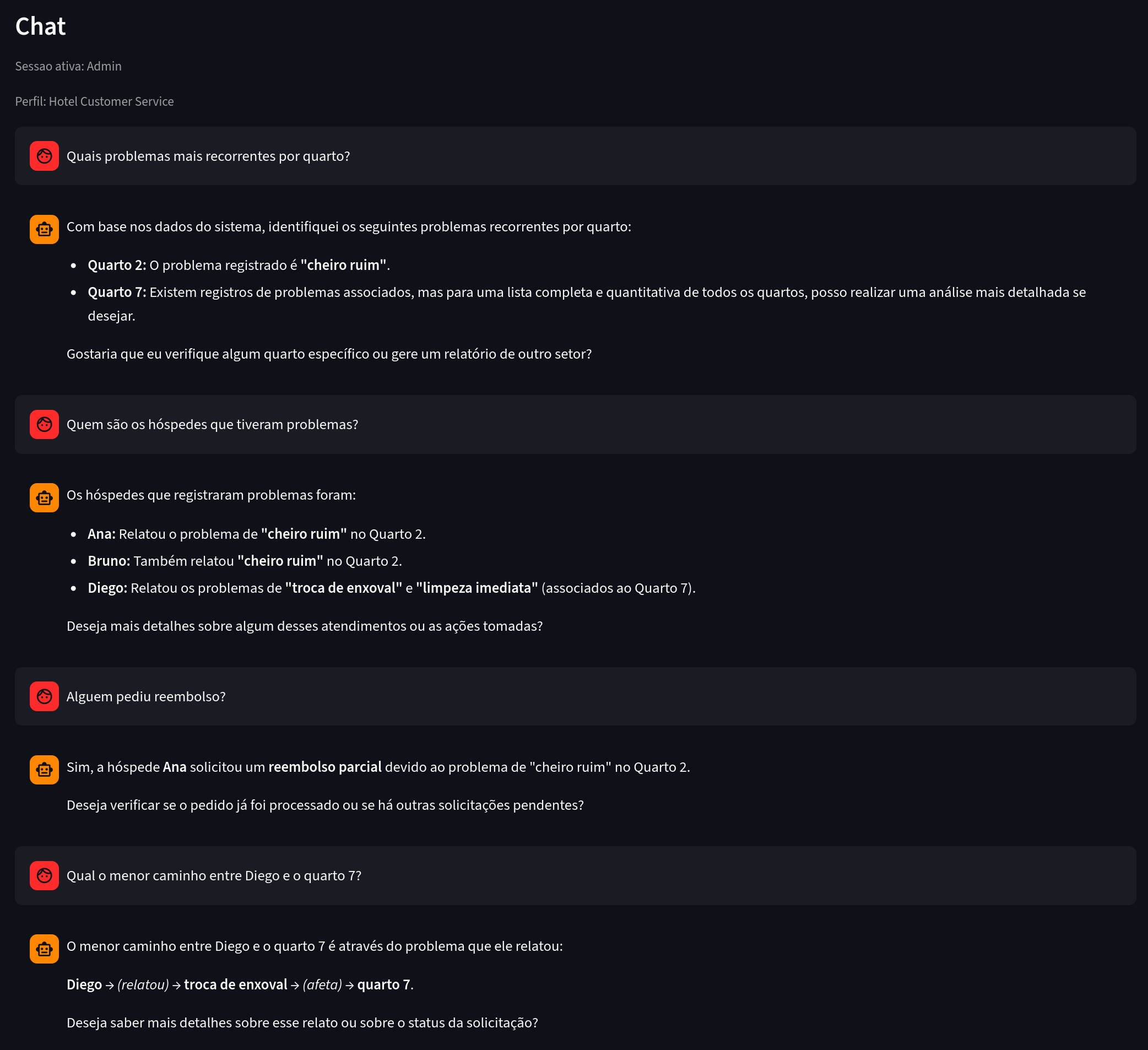
Figura 8. Qué observar: preguntas analíticas respondidas a partir de conexiones explícitas.
Otros sectores donde este enfoque encaja muy bien
E-commerce
Mismo principio, otro dominio:
- usuario interesado en un producto,
- comparación con la competencia,
- problema de entrega o pago,
- solicitud de acción (cambio, cancelación, reembolso).
Con el perfil de prompt adecuado, es posible mapear:
- productos con mayor intención de compra,
- competidores más mencionados,
- cuellos de botella en la experiencia por etapa,
- patrones por segmento de cliente.
Otros escenarios naturales: soporte SaaS, telecomunicaciones, salud, educación y soporte financiero.
Aprendizajes: la importancia del conocimiento de dominio
Un aprendizaje clave fue este: sin contexto de dominio, la IA puede crear conexiones que no tienen relevancia para el negocio.
Si no se explica con claridad qué tipo de información debe entrar en el grafo, el LLM mezcla:
- hechos concretos (útiles), con
- artefactos de proceso o interpretaciones vagas (ruido).
Domain policy en la práctica
La domain policy es el contrato semántico de tu grafo.
Ejemplo en el hotel:
- User -> reported_issue -> Issue
- Issue -> affects_location -> Location
- User -> requested_action -> Activity
Con esto, el pipeline gana previsibilidad y el grafo se vuelve mucho más útil para consultas analíticas.
En esencia, le explicas a la IA qué tipos de relaciones importan para tu negocio.
Cómo se realiza la resolución de entidades hoy
Actualmente usamos un enfoque híbrido y pragmático:
- Búsqueda de candidatos en el grafo (find_entity) por nombre y tokens relevantes.
- Score local que combina similitud de cadena y solapamiento de tokens.
- Reutilización de la entidad existente cuando el score supera el umbral por tipo.
- En casos más ambiguos, el resolution_agent usa herramientas adicionales para decidir.
Funciona bien como punto de partida y es sencillo de operar.
Limitaciones actuales:
- depende bastante de la similitud léxica,
- tiene más dificultades con sinónimos y paráfrasis distantes,
- requiere ajustes finos del umbral por tipo de entidad.
Mejoras futuras: embeddings para resolver entidades y relaciones
Una evolución natural es incorporar resolución semántica con embeddings.
Idea de arquitectura:
- Generar embedding para entidades candidatas y para nuevas menciones.
- Buscar vecinos más cercanos en un índice vectorial.
- Re-ranking con reglas de dominio (tipo de entidad, contexto local y relaciones existentes).
- Confirmar la fusión o reutilización con confianza calibrada.
Beneficios esperados:
- mejor manejo de sinónimos y variaciones lingüísticas,
- menor duplicación semántica,
- menor dependencia de heurísticas de string matching.
Extensión futura: usar embeddings también para sugerir relaciones probables, siempre con un policy gate para evitar alucinaciones estructurales.
Conclusión
El punto principal no es solo tener un chatbot que responda bien.
La ventaja diferencial está en transformar conversaciones en estructuras consultables, con calidad semántica y trazabilidad.
En el caso del hotel, eso significa:
- identificar recurrencias por ubicación,
- conectar la experiencia del huésped con el impacto operacional,
- responder preguntas analíticas con evidencia en el grafo.
En resumen: la memoria textual ayuda. La memoria estructurada habilita insights de negocio que antes eran difíciles de obtener.
Tags: #chatbot #grafoDeConocimiento #knowledgeGraph #Neo4j #inteligenciaArtificial #LLM #NLP #extraccionDeInformacion #tripletas Semanticas #analisisDeDatos #insightsDeProduto #atencionAlCliente #arquitecturaDeDatos #RAG #semantica #procesamientoDeLenguajeNatural #datosEstructurados #resolucionDeEntidades #embeddings #businessIntelligence